 |
| About Bioline | All Journals | Testimonials | Membership | News |
|
||||||
|
||||||
Volume 6 Number 4, July/August 1996, pp.211-217 COMPUTING FOR BIOTECHNOLOGY- WEBANGIS
T.G. Littlejohn, C. A. Bucholtz, R.M.M. Campbell, B.A Gaeta,
C. Huynh and S.H. Kim,
Code Number: AU96006
Size of Files:
Text: 21.6K
Graphics: Line drawings (gif) - 35.0K
Photographs (jpg) - 447.8K
[ALL FIGURES AND TABLES AT END OF TEXT] Abstract Recent advances in molecular biology tools have opened the flood-gates on data production, and novel product discovery and development strategies using "genomic" approaches are becoming commonplace. Consequently, computing systems are an essential component of modern biotechnology operations: they are requiredl for data collection, management and analysis. These systems rely on efficient access to the global collection of genomic databases (DNA and protein sequences, for example), software tools and network-based material. These resources are growing in size and number daily, and sophisticated computing systems are required for managing the growing data production capacity with this expanding resource base. The World Wide Web (WWW) based solution described here, WebANGIS , is a system for the biotechnology and academic sectors for data management and analysis. WebANGIS uses an integrated WWW based system that allows secure and efficient high throughput analysis of molecular sequence information through the Internet. Introduction- Computing for Biotechnology Modern biotechnology has turned to molecular biology and genetics as a source of the next generation of novel products. It is now commonplace for the "genomic" approach - large scale DNA mapping, cloning and sequencing- to be applied to the discovery of new genes of potential economic value. Gene discovery through large-scale or whole-genome sequencing can lead to a vast number of candidate genes for potential exploitation in a very short amount of time. The technology has proven itself: the sequence of two bacterial genomes (Fleischmann, et al., 1995; Fraser, et al. 1995) and of yeast (http://genome-www.stanford.edu/Saccharomyces/) have recently been completed and are available for public analysis. The contribution of the biotechnology industry in this effort is also very well established: both these bacterial genomes were sequenced by the private organisation TIGR (The Institute for Genomic Research) in Maryland, USA (http://www.tigr.org). A number of other bacterial genomes are presently being sequenced, including members of the archaebacteria, which have enormous economic potential for identification of protein products that function under extreme (e.g. temperature and pH) conditions (e.g. the Sulpholobus genome; http://www.imb.nrc.ca/imb/sulfolob/sulhom_e.html). Indeed, the entire human genome project (http://www.ornl.gov/hgmis/) will provide a rich resource base not just for addressing fundamental questions about the nature of life but also for the discovery of novel therapeutic agents. Coupled with powerful human-genetics techniques, it is becoming easier to track down candidate genes responsible for debilitating disorders and design ways of combating these errors of metabolism. Computational Resources for Biotechnology- Bioinformatics Computers have become an indispensable component of the modern biotechnology operation. They are essential for collecting, managing and storing raw genetic data. Much of this data (e.g. DNA sequence data) is generated in an electronic form and is stored directly onto the computer. Computers are required for the analysis of the data, extracting biological information from it through queries to sequence databases and through software systems for gene prediction, structural analysis and phylogenetic reconstruction amongst others. The hunt for human genes often recruits software systems for the analysis of pedigrees for tying genetic diseases to their underlying genes. Once identified, important gene products can be manipulated in the computer using molecular modelling methods in the search for novel function. The application of computers to solving problems in biology is known as bioinformatics. The importance of bioinformatics in genomics and biotechnology is now widely recognised, as exemplified by its position as a separate program of the Human Genome Project (http://www.ornl.gov/hgmis/resource/informatics.html). Our ability to generate molecular data is fast outstripping our capacity to manage and interpret that data. Advances in DNA mapping, cloning and sequencing technologies have become routine and easily automated (Mattick, 1996), and the promise of similar technologies for high throughput protein analysis are on the horizon (Williams and Walsh, 1996). As a consequence of improved data production techniques, the number of molecular biology, genetics and genomics databases and the volume of these databases has been expanding rapidly. For example, GenBank, the major DNA sequence database maintained by the National Centre for Biotechnology Information (NCBI) in the USA (Benson et al. 1994), is presently doubling in size every fourteen months (ftp://ncbi.nlm.nih.gov/genbank/gbrel.txt). Repositories of protein sequence data are growing at a similar rate, as is the collection of tertiary structures. In addition to the volume of data growing within these databases, the number of databases itself is growing. Specialised genome databases are continually coming on-line as new genome projects and initiatives become established in organisms of medical and agricultural importance. In addition to databases, a growing body of specialised software packages have been developed to aid in the query, analysis and management of genomic information. For example, one catalogue of relevant software contains over 480 entries (http://www.ebi.ac.uk/biocat/), and this collection only covers a portion of present developments. The serious challenge facing modern biotechnology is to establish information systems that can manage the product of these growing and diverse resources (summarised in Figure 1) that handle:
2. An increasing ability to generate data; 3. The increasing numbers and complexities of software tools for querying biotechnology data, its analysis, and management; 4. The growing collection of network-based resource bases, both internal (corporate-intranet) and external (Internet). As all these components are expanding substantially, there is a great need for intelligently engineered solutions that can keep data production and analysis in step with each other. An Australian solution to this challenge, WebANGIS, is presented here.
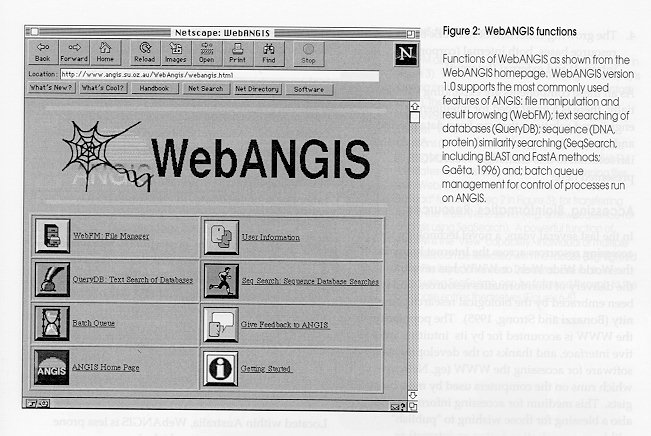
In the last several years, a novel technology for accessing resources across the Internet known as the World Wide Web, or WWW, has revolutionised the delivery of bioinformatics resources, and it has been embraced by the biological research community (Bonazzi and Strong, 1995). The popularity of the WWW is accounted for by its intuitive, interactive interface, and thanks to the development of software for accessing the WWW (eg. Netscape) which runs on the computers used by most biologists. This medium for accessing information is also a blessing for those wishing to "publish" within an organisation (using an intranet) or globally (using the Internet). It is increasingly easy for companies, individuals, research groups or institution to provide information, databases and even analysis tools through the WWW (Green and Atkinson, 1995). However, the typical way of accessing the WWW has many serious limitations which make it less than ideal for many purposes. The most common use of the WWW is to formulate database queries or to access analysis functions by "cutting and pasting" sequence data into a WWW form presented from a variety of sites on the Internet. Difficulties with this approach are that: (i) the quantity of sites is so large that it is unmanageable, making it difficult to be aware of new or outdated sites, and the quality of these sites is highly variable and unpredictable; (ii) the speed of accessing resources on the WWW can be extremely slow, even unusable, owing to the fact that most sites lie outside of Australia and international Internet access can be unreliable; (iii) the majority of WWW sites around the world are anonymous, i.e. they are accessed without support or help, confidential data sent to these sites may not be secure, and there is no guarantee that the information being accessed are current; (iv) to query databases at anonymous WWW sites, it is generally necessary to stay on-line until results are returned, making it difficult to automatically store data and the results of queries in the same location, or to perform database scans or analyses on a routine or "batch" mode which does not require a continual connection to the network; and (v) it is very difficult to perform high throughput analysis (it would be a daunting task to cut and paste 1000 sequences into an anonymous WWW site, especially when the next sequence cannot be submitted until the previous run has completed). These problems with the "anonymous" WWW are solved by creating "dedicated" WWW servers (Littlejohn, 1996). The Australian National Genomic Information Service (ANGIS), Australia's National Centre for bioinformatics support (Littlejohn 1996), has a dedicated WWW server ("WebANGIS") that offers a wide and growing range of bioinformatics services (Figure 2) which does not suffer from the limitations of anonymous WWW sites. Located within Australia, WebANGIS is less prone to the Internet bottlenecks which slow access to anonymous sites outside the country. As the databases and software on WebANGIS are carefully selected, there is no difficulty in identifying and selecting the appropriate resources for a particular task. All data, databases and results are stored on the same computer (the WebANGIS server), so access to all these resources is rapid and available from any computer on the Internet. Because database and software coexist on the same system, analyses and database queries can be performed at any time even without having to be connected to WebANGIS. This is particularly useful for routine database searches such as those established through the ANGIS Notify system (Littlejohn, 1996). All data and results are password protected, so security is in place, and support is provided through phone and email as well as in-house workshops and courses run at ANGIS. In addition, the system is fully documented with on-line help available throughout. The ANGIS WWW home page provides a simple access route to WebANGIS, and a number of other core features of the ANGIS system. These include databases (e.g. the Human Genome Database, GDB; Fasman et al., 1996) software, routine database query systems (ANGIS Notify), pointers to other WWW resources and documentation and education services amongst others. Figures 4 to 8 show examples of how WebANGIS could be used for molecular sequence analysis corresponding to components of the flow chart in Figure 3. WebANGIS presently covers major database search techniques such as sequence-similarity searching (Figure 5) using the BLAST and FastA methods (Ga‰ta, 1995) and key-word searches suing the QueryDB system. These systems access all major sequence databases, such as the EST, GenBank, EMBL and SWISS-PROT databases. In addition, WebANGIS offers a powerful tool for managing data and results, WebFM (Figure 5). WebFM has the inbuilt capacity to handle high throughput analyses by presenting summaries from one to hundreds of separate searches. High throughput analysis can be performed automatically using the ANGIS Notify system (Littlejohn, 1996), a routine database scanning sub-system of ANGIS. Spinning a Wider Web
The version of WebANGIS discussed here represents the first release of a system that is continuing to expand in scope and functionality. Ongoing developments include interactive applications written in the java language (http://java.sun.com/) to facilitate protein structure analysis, sequence editing, comparative sequence analysis and genome analysis. Other projects at AGIC include custom systems for high throughput genome data analysis and gene discovery systems for gene-hunting in large-scale human genome sequencing projects. The future for the WWW interface for the delivery of bioinformatics resources is assured by it's platform independence, usability, and short development cycles and -most importantly- wide acceptance. The WebANGIS system will continue to increase in utility as additional components (databases, software and information management systems) are integrated in the near future.
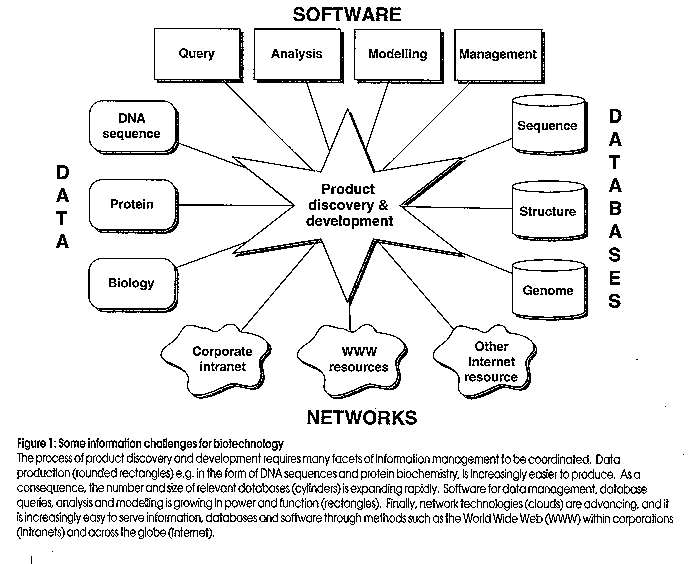
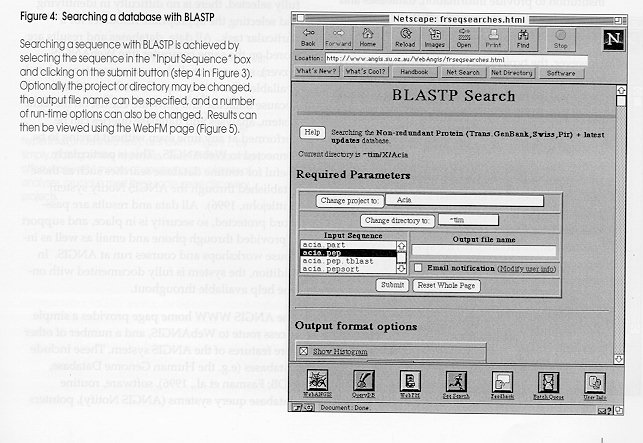
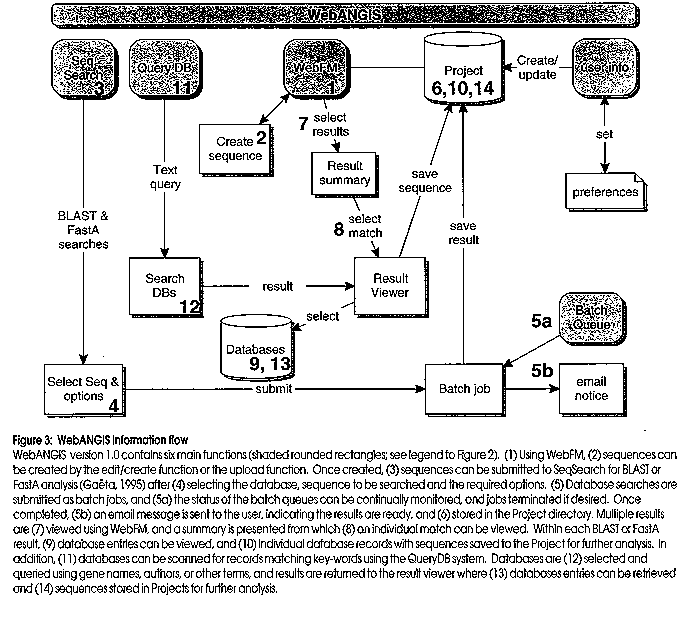
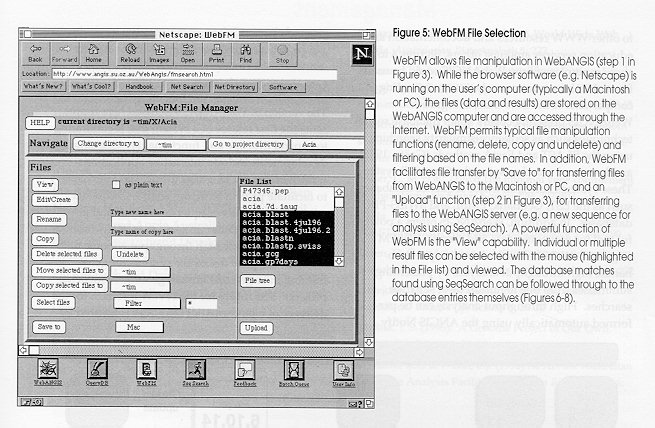
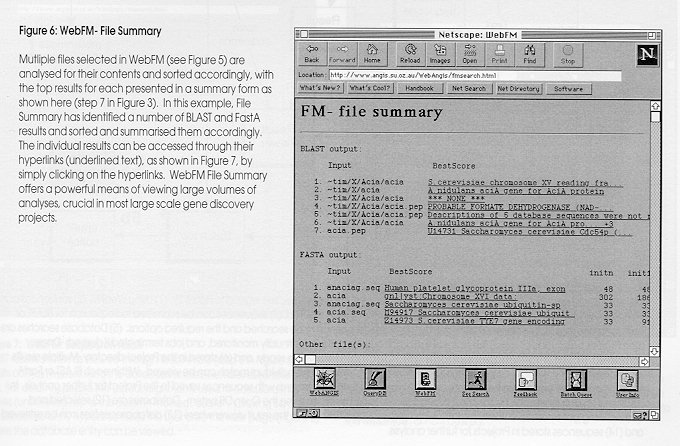
The process of product discovery and development requires many facets of information management to be coordinated. Data production (rounded rectangles) e.g. in the form of DNA sequences and protein biochemistry, is increasingly easier to produce. As a consequence, the number and size of relevant databases (cylinders) is expanding rapidly. Software for data management, database queries, analysis and modelling is growing in power and function (rectangles). Finally, network technologies (clouds) are advancing, and it is increasingly easy to serve information, databases and software through methods such as the World Wide Web (WWW) within corporations (intranets) and across the globe (Internet). Figure 2: WebANGIS functions Functions of WebANGIS as shown from the WebANGIS homepage. WebANGIS version 1.0 supports the most commonly used features of ANGIS: file manipulation and result browsing (WebFM); text searching of databases (QueryDB); sequence (DNA, protein) similarity searching (SeqSearch, including BLAST and FastA methods; Ga‰ta, 1996) and; batch queue management for control of processes run on ANGIS. Figure 3: WebANGIS information flow WebANGIS version 1.0 contains six main functions (shaded rounded rectangles; see legend to Figure 2). (1) Using WebFM, (2) sequences can be created by the edit/create function or the upload function. Once created, (3) sequences can be submitted to SeqSearch for BLAST or FastA analysis (Ga‰ta, 1995) after (4) selecting the database, sequence to be searched and the required options. (5) Database searches are submitted as batch jobs, and (5a) the status of the batch queues can be continually monitored, and jobs terminated if desired. Once completed, (5b) an email message is sent to the user, indicating the results are ready, and (6) stored in the Project directory. Multiple results are (7) viewed using WebFM, and a summary is presented from which (8) an individual match can be viewed. Within each BLAST or FastA result, (9) database entries can be viewed, and (10) individual database records with sequences saved to the Project for further analysis. In addition, (11) databases can be scanned for records matching key-words using the QueryDB system. Databases are (12) selected and queried using gene names, authors, or other terms, and results are returned to the result viewer where (13) databases entries can be retrieved and (14) sequences stored in Projects for further analysis. Figure 4: Searching a database with BLASTP Searching a sequence with BLASTP is achieved by selecting the sequence in the "Input Sequence" box and clicking on the submit button (step 4 in Figure 3). Optionally the project or directory may be changed, the output file name can be specified, and a number of run-time options can also be changed. Results can then be viewed using the WebFM page (Figure 5). Figure 5: WebFM File Selection WebFM allows file manipulation in WebANGIS (step 1 in Figure 3). While the browser software (e.g. Netscape) is running on the user's computer (typically a Macintosh or PC), the files (data and results) are stored on the WebANGIS computer and are accessed through the Internet. WebFM permits typical file manipulation functions (rename, delete, copy and undelete) and filtering based on the file names. In addition, WebFM facilitates file transfer by "Save to" for transferring files from WebANGIS to the Macintosh or PC, and an "Upload" function (step 2 in Figure 3), for transferring files to the WebANGIS server (e.g. a new sequence for analysis using SeqSearch). A powerful function of WebFM is the "View" capability. Individual or multiple result files can be selected with the mouse (highlighted in the File list) and viewed. The database matches found using SeqSearch can be followed through to the database entries themselves (Figures 6-8). Figure 6: WebFM- File Summary Multiple files selected in WebFM (see Figure 5) are analysed for their contents and sorted accordingly, with the top results for each presented in a summary form as shown here (step 7 in Figure 3). In this example, File Summary has identified a number of BLAST and FastA results and sorted and summarised them accordingly. The individual results can be accessed through their hyperlinks (underlined text), as shown in Figure 10, by simply clicking on the hyperlinks. WebFM File Summary offers a powerful means of viewing large volumes of analyses, crucial in most large scale gene discovery project. Figure 7: WebFM: SeqSearch result BLAST results shown as viewed through WebANGIS (step 8 in Figure 3). The results contain hyperlinks to the database entries themselves (underlined text, first column) and to the actual alignments used to calculate the scores (underlined text in the column marked "Score". Clicking on any of the database entry hyperlinks takes the user onto the next page (Figure 8) where the database entry can be viewed. Figure 8: WebFM: Database entry Database entries can be accessed by clicking on the hyperlinks in the BLAST result page (Figure 7; step 9 in Figure 3). These records can then be saved into the Project directory for subsequent analysis or directly to the Macintoch or PC if desired.
ANGIS is presently supported by its subscribers, the Australian Research Council, the Australian National Health and Medical Research Council, SydUtech, and Apple Australia and in the past by the Wool Research and Development Corporation, Grains Research and Development Corporation, Pig Research and Development Corporation, Meat Research Corporation, and the Dairy Research and Development Corporation.
References
Benson, D. A., Boguski, M., Lipman, D.J and Ostell, J. (1996) GenBank. Nucleic Acids Research 24: 1-5. Bonazzi, V. and Strong, P. (1995) A World Wide Web Guide. Australasian Biotechnology 5: 272 Fasman, K.H, Letovsky, S.I., Cottingham, R.W. and Kingsbury, D.T. (1996) Improvements to the GDB Human Genome Data Base Nucleic Acids Research 24: 57-63 Fleischmann, R. D. et al. (1995) Whole-genome random sequencing and Assembly of Haemophilus influenzae Rd. Science 269: 496-512 Fraser, C. M. et al. (1995) The minimal gene complement of Mycoplasma genitalium Science 270: 397-403 Gaeta, B. (1995) Database Similarity Searching Using BLAST and FastA Australasian Biotechnology 5: 282-290 Green, D. G. and Atkinson, J. (1995) Networking the biotechnology revolution Australasian Biotechnology 5: 272 Littlejohn, T.G. (1996) Bioinformatics: the essential ingredient. Today's Life Science 8: 28-33 Mattick, J. S. (1996). A Genome Project of Our Own. Today's Life Science 8: 23-26 Williams, K.L., & Walsh, B.J. (1996) APAF: the Australian Proteome Analysis Facility Australasian Biotechnology 6: 178-180 Copyright 1996 Australian Biotechnology Association Ltd. The following images related to this document are available:Photo images[au96006d.jpg] [au96006b.jpg] [au96006e.jpg] [au96006g.jpg] [au96006h.jpg] [au96006f.jpg]Line drawing images[au96006c.gif] [au96006a.gif] |
| |||||||||
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}