 |
| About Bioline | All Journals | Testimonials | Membership | News |
|
||||||
|
||||||
Modificacion Del Gen De La Esporamina De Boniato Con Un Fragmento De ADN Sintetico. Secuencia Nucleotidica Y Expresion En Escherichia coli Alina Lopez,^1 Zurima Zaldua,^1 Eulogio Pimentel,^1 Melba Garcia,^1 Rolando Garcia,^1 Jesus Mena,^1 Rolando Moran^1 y Guillermo Selman^2
^1Centro de Ingenieria Genetica y Biotecnologia. Apartado
postal 387. Camaguey, Cuba.
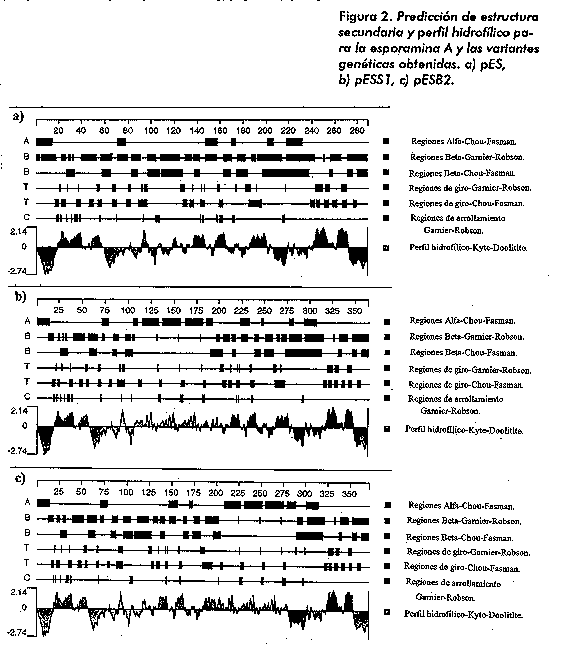
ABSTRACT Sporamin, the major soluble protein of sweet potato tuberous roots (Ipomoea batatas), has a relatively balanced aminoacid content, but it is limited in lysine and methionine. A 240 base pair DNA fragment was designed and synthesized in order to improve the aminoacidic quality of the sporamin. From a total DNA preparation and using polimerase chain reaction, the region containing the sporamin gene and its regulatory regions was amplified. The DNA obtained was cloned and sequenced. Besides, we amplified by PCR a fragment containing the sporamin gene, the sequences coding for transit to vacuoles and the signal peptides. This region was cloned, sequenced and expressed in Escherichia coli. With the use of specific restriction endonucleases, two strategies were developed to insert the DNA synthetic fragment in two different positions of the structural gene for sporamin. Predictions of the possible features of the modified sporamins were performed using appropriate softwares. The genetic variants obtained were checked by restriction, hibridization and sequencing. Their expression in E. coli was detected by Western blotting. Key words: essential aminoacids, protein quality RESUMEN La esporamina, principal proteina del tuberculo de boniato (Ipomoea batatas), presenta un contenido de aminoacidos relativamente balanceado pero limitado a su vez en lisina y metionina. Se diseno y sintetizo un fragmento de ADN de 240 pares de bases con el objetivo de mejorar la calidad aminoacidica de la esporamina. A partir de una preparacion de ADN total de boniato y por reaccion en cadena de la polimerasa, se amplifico la region que contiene el gen que codifica la esporamina y las secuencias reguladoras adyacentes. El ADN amplificado se clono y secuencio. Tambien por PCR, se amplifico un fragmento que contiene solo el gen estructural de la esporamina y las secuencias que codifican los peptidos senal y de transito a vacuolas. Esta region se clono, secuencio y expreso en Escherichia coli. Con el uso de endonucleasas especificas de restriccion se realizaron dos estrategias en las que el fragmento de ADN sintetico fue insertado en posiciones diferentes de la secuencia del gen estructural para la esporamina. Las predicciones de los posibles atributos de las esporaminas modificadas fueron realizadas a traves de programas de computo. Las variantes geneticas obtenidas fueron chequeadas por restriccion enzimatica, hibridacion y secuencia. Su expresion en E. coli fue detectada por Western blotting. Palabras claves: aminoacidos esenciales, calidad proteica Introduccion El boniato (Ipomoea batatas) es una planta dicotiledonea perteneciente a la familia Convalvulaceae. Su cultivo, de acuerdo al volumen de las cosechas, ocupa el septimo lugar a nivel mundial entre los destinados a la alimentacion (1) y el segundo entre los vegetales. Anualmente se producen alrededor de 132 millones de toneladas metricas de este tuberculo (2). El alto contenido de materia seca y carbohidratos le confiere fundamental importancia en usos industriales y en la alimentacion animal. El boniato es tambien una importante fuente de provitamina A, vitamina C, potasio, hierro y calcio. El contenido de proteinas del tuberculo varia entre el 2 y el 10 % del peso seco en dependencia del genotipo (3, 4). La principal proteina del tuberculo es la esporamina; posee un peso molecular de aproximadamente 20 000 Da y constituye el 60-80 % del total de proteinas solubles del organo (5, 6). Se ha comprobado que es sintetizada como un precursor de aproximadamente 4 000 Da mayor que la proteina madura (7, 8). La region N-terminal de la proteina contiene dos secuencias aminoacidicas: peptido senal y peptido transitorio, responsables de su entrada en reticulo y de su localizacion vacuolar final (9). De manera similar a los genes de la patatina de papa, la esporamina es codificada por una familia multigenica, aunque a diferencia de la patatina no presenta intrones. En el caso de la esporamina se reportaron dos subfamilias: A y B, que tienen homologias superiores al 94 % intrasubfamilia y alrededor del 83 % intersubfamilia (8, 10, 11). En plantas de boniato sometidas a condiciones normales de crecimiento en campo, los ARN mensajeros para la esporamina estan presentes casi exclusivamente en el tuberculo y muy poco en otros organos. Esta caracteristica evidencia la regulacion organo-especifica a que estan sometidos estos genes (10). Al ser la esporamina la proteina mayoritaria del tuberculo, su calidad aminoacidica influye en la calidad proteica de este organo. El contenido de aminoacidos tanto en la esporamina A como en la B es relativamente balanceado, sin embargo presenta limitaciones en lisina (Lys) y metionina (Met) (6). Estas limitaciones hacen necesario el suplemento proteico a aquellas dietas basadas en boniatos. La ingenieria genetica puede ser usada como herramienta para corregir esta deficiencia nutricional. El gen de la esporamina A constituye un mejor candidato para ser utilizado como punto de partida en la estrategia de modificacion, dada su mejor calidad aminoacidica en relacion con la B. La estabilidad de las proteinas heterologas utilizadas para incrementar el valor nutricional en algunos cultivos ha sido baja. En este trabajo, la mejoria de la calidad nutricional se aborda a traves de una estrategia diferente a las reportadas hasta el momento; de ahi su importancia. La fusion del fragmento nucleotidico en zonas internas del gen de la esporamina persigue como proposito que la proteina quimerica posea mayor estabilidad. En el presente trabajo se describe el procedimiento realizado para obtener dos variantes geneticas modificadas de la esporamina A con un fragmento de ADN sintetico cuyos codones codifican un elevado numero de Lys y Met entre otros aminoacidos. Ambas variantes fueron clonadas en vectores plasmidicos, secuenciadas y expresadas en Escherichia coli. Las construcciones geneticas obtenidas seran utilizadas para lograr plantas transgenicas de boniato que tengan mejor calidad nutricional. Materiales y Metodos Purificacion de la esporamina y obtencion de anticuerpos especificos La esporamina de boniato fue purificada a partir de tuberculos frescos de la variedad CEMSA 78-354. El proceso de purificacion fue desarrollado segun (5). Los resultados se chequearon por electroforesis en gel de poliacrilamida al 12,5 %, en condiciones desnaturalizantes (12). El grado de pureza de la fraccion final de la esporamina fue estimado por densitometria. Los anticuerpos especificos fueron obtenidos en conejo y purificados por el metodo de Harlow y Lane (13). El titulo se determino por inmunodot blot (14) frente a una curva de concentraciones crecientes de esporamina. Purificacion de ADN total de boniato Se realizo extraccion y purificacion de ADN total a partir de hojas de boniato de la variedad CEMSA 78-354 segun el procedimiento reportado por Dellaporta SL, et al (15). Se utilizaron 5 mg de hoja como material de partida. Reaccion en cadena de la polimerasa y clonacion Se llevo a cabo a partir de ADN total de boniato. Los oligonucleotidos utilizados fueron disenados de acuerdo con la secuencia reportada (10), incluyendo ligeros cambios para facilitar su posterior clonacion. Como resultado, se originaron extremos susceptibles a digestion HindIII en 5' y EcoRI en 3'. El procedimiento se efectuo segun (16) y el fragmento obtenido se digirio EcoRI- HindIII y clono en un vector pUC19 previamente tratado con las mismas enzimas de restriccion. Los clones recombinantes (pSpor1) se chequearon por restriccion con endonucleasas y por hibridacion de colonias con un oligonucleotido disenado para reconocer una region interna del fragmento clonado. Se les determino la secuencia nucleotidica. A partir de pSpor1 se amplifico, segun Saiki RK and Erlich HA (17), el fragmento que contiene el gen estructural para la esporamina. El oligonucleotido 3' empleado fue el mismo que en la reaccion anterior. El utilizado para la region 5' fue modificado en un nucleotido respecto a la secuencia original para introducir el sitio NcoI. El fragmento resultante fue digerido EcoRI y clonado en un vector pUC19 tratado SmaI-EcoRI. Los clones recombinantes (pES) fueron chequeados con endonucleasas apropiadas y se expresaron en E. coli. Determinacion de la secuencia nucleotidica Se llevo a cabo por el metodo de Sanger (14) a partir de 10 g de ADN del plasmido recombinante pSpor1 y preparado por lisis alcalina con el empleo de columnas Qiagen. Las reacciones de secuencia fueron procesadas en un secuenciador automatico Pharmacia LKB usando el kit de secuenciacion AutoReadTM. Con las mismas condiciones, este procedimiento se llevo a cabo para secuenciar las variantes modificadas de la esporamina obtenidas. Diseno y sintesis del fragmento de ADN para la modificacion de la esporamina Se diseno un fragmento de 240 pares de bases. Su secuencia es similar a la del High Essential Aminoacid Encoding DNA (HEAAE- DNA), reportada para el mejoramiento de la calidad nutricional de la patatina de papa (18). Este fragmento codifica un peptido con alto contenido en aminoacidos esenciales, frecuentemente deficientes en proteinas de origen vegetal. La insercion del fragmento disenado en la secuencia de la esporamina incrementaria entre dos y tres veces el contenido de Lys y Met, respectivamente. La sintesis se llevo a cabo en un ensamblador de nucleotidos (Pharmacia LKB-Gene Assembler Plus) y su posterior purificacion fue realizada por HPLC usando columnas de fase reversa. Expresion de la esporamina en E. coli Un cultivo de E. coli MC 1066 que contiene el plasmido pES se crecio a 37 C y se indujo con 0,4 mM de IPTG. Las celulas se cosecharon por centrifugacion y se resuspendieron en tampon PBS 1X. Se realizo ruptura por ultrasonido y se colecto el sobrenadante. Se determino la concentracion de proteinas totales (19). El chequeo de la expresion se realizo por Western blot de acuerdo al protocolo establecido (14), empleando anticuerpos de conejo especificos para esporamina. Modificacion genetica de la esporamina Para insertar el fragmento de ADN sintetizado en el gen de la esporamina, se considero la presencia de puentes disulfuros, punto isoelectrico, perfiles hidrofobicos e hidrofilicos y de estructura secundaria, asi como evitar variaciones bruscas de la talla molecular; todo esto respecto a la proteina nativa. Para ello se utilizo el programa de computo "DNA Strider" (20). A partir de pES se disenaron dos estrategias de modificacion. Primero pES se digirio SalI, eliminandose un fragmento de 29 pares de bases; luego se trato con el fragmento Klenow de la ADN polimerasa I y con fosfatasa alcalina. El fragmento de ADN sintetico fue digerido DraI - HincII para su clonacion en el sitio creado en pES. El ligamiento se llevo a cabo empleando T4 DNA ligasa. La segunda variante abarco la digestion BstXI de pES, luego se trato con S1 nucleasa con el proposito de originar extremos romos y con fosfatasa alcalina. El fragmento de ADN sintetico tambien fue digerido DraI - HincII e insertado con el empleo de T4 DNA ligasa. Los clones recombinantes derivados de ambas variantes: pESS1 y pESB2, fueron chequeados por hibridacion de colonias con un oligonucleotido que reconoce el fragmento sintetico insertado. La orientacion del inserto fue corroborada por restriccion enzimatica. La secuencia nucleotidica de los clones pESS1 y pESB2 fue realizada segun se describio anteriormente. Clonacion en vectores pET Plasmidos de la serie pET (21) fueron purificados segun Sambrook, et al. (14) y digeridos Nco I-Eco RI. De pESS1 y pESB2 se extrajo la banda NcoI-EcoRI que fue clonada en los vectores pET previamente preparados, y se origino pETS1 y pETB2, respectivamente. El chequeo de la clonacion se realizo por restriccion enzimatica. Expresion de las variantes modificadas de la esporamina en E. coli Las celulas de E. coli que contienen el plasmido PGP1-2 (22) se transformaron con los plasmidos recombinantes pETS1 y pETB2. Se crecieron a 28 C durante 3 h, se sometieron a 42 C por 30 min para inducir la expresion y finalmente a 37 C por 1,5 h. El precipitado celular obtenido por centrifugacion del cultivo fue resuspendido en 10 mL de solucion tampon PBS 1X y sometido a ruptura por ultrasonido segun se describe anteriormente. Se colecto el sobrenadante de ruptura por centrifugacion y se determino la concentracion de proteinas totales (19). El chequeo de la expresion fue realizado por Western blot (14) empleando los anticuerpos especificos para esporamina. Resultados y Discusion El ADN total, extraido a partir de hojas de boniato, se obtuvo con alto grado de pureza y altos rendimientos, lo que coincide con lo reportado por Varadarajan GS y Prakash CSA (23). Este ADN se tomo para amplificar, mediante la reaccion en cadena de la polimerasa, el gen de la esporamina A y las regiones regulatorias adyacentes. Se obtuvo un fragmento de 1 182 pares de bases cuya talla coincidio con el rango a esperar. La utilizacion de pequenas cantidades de material vegetal (5 mg) para la extraccion del ADN total y la posibilidad de amplificar a partir de el al gen de la esporamina puede permitir hacer pesquisajes a las futuras plantas transgenicas en estadios tempranos de su desarrollo. Segun el analisis de homologia realizado entre la secuencia del gen estructural obtenida por reaccion en cadena de la polimerasa (PCR) y la reportada para un gen de la subfamilia A de las esporaminas (11) (Figura 1), existe un 92,3 % de identidad. En cuanto a la prediccion de la composicion aminoacidica entre ambas proteinas se muestra un 86,3 % de homologia con 30 aminoacidos diferentes. La PCR fue realizada en mas de una ocasion y varios clones secuenciados, observandose en todos los casos los mismos cambios de nucleotidos al realizar el alineamiento de las secuencias. Los valores de homologias obtenidos resultan similares a los que se reportan intrasubfamilia y superiores a los existentes entre subfamilias. Por esta razon, el gen aislado debe pertenecer a la subfamilia A de las esporaminas, siendo atribuibles las diferencias a aquellas que existen entre las variedades de boniato.
A partir del plasmido pSpor1 se amplifico por PCR un fragmento de 864 pares de bases correspondiente al gen estructural de la esporamina y las secuencias codificantes para los peptidos senal y transitorio, asi como la region regulatoria 3'. Tanto la secuencia reportada como la obtenida de pSpor1 sirvieron de base para el diseno de los oligonucleotidos cebadores. Los clones recombinantes pES mostraron, con diferentes endonucleasas, el patron de restriccion esperado. En el Western blot para detectar la expresion en E. coli de la esporamina, la proteina procedente de tuberculos utilizada como control positivo migro a una talla de alrededor de 4 KDa superior a la esperada segun las predicciones para la proteina madura (Tabla 1). Tabla 1. Propiedades moleculares y composicion aminoacidica de la esporamina A y de las variantes geneticas obtenidas. a) pES, b) pESS1, c) pESB2.
Predicciones pES pESS1 pESB2 ---------------------------------------------------------- Peso molecular (Da) de la proteina no procesada 24364,12 33307,10 33979,89 Peso molecular (Da) de la proteina madura 20550,52 29493,50 30166,29 Punto isoelectrico de la proteina no procesada 8,44 8,4 8,13 a.a. cargados (RKHYCDE) 26,24 29,05 28,49 a.a. acidos (DE) 7,09 9,78 9,86 a.a. basicos (KR) 9,22 11,45 10,96 a.a. polares (NCQSTY) 32,27 27,09 27,12 a.a. hidrofobicos (AILFWV) 36,52 34,92 35,07 Lys 4,96 7,26 7,12 Met 2,13 4,19 4,38 Trp 0,35 1,12 1,10 Este comportamiento, atribuido a la adopcion de conformaciones que retardan ligeramente la migracion en gel por la presencia de puentes disulfuros y determinadas condiciones de desnaturalizacion, ha sido reportado para esta proteina (7, 8). La expresion en E. coli de pES dio lugar a una proteina de alrededor de 28 KDa (unos 4 KDa por encima de la esporamina natural). La diferencia en talla entre ambas puede deberse a la presencia de 114 nucleotidos en la secuencia 5' del gen; estos codifican 38 aminoacidos responsables de la localizacion subcelular de la proteina en celulas de plantas que no son procesados en E. coli. De estos resultados puede inferirse que la diferencia de alrededor de 8 KDa superior que se muestra en la expresion de pES en el Western blot en relacion con la prediccion de talla para la proteina madura, aproximadamente la mitad se atribuye a regiones no procesadas y la otra, a un retardo en la migracion electroforetica debido a razones conformacionales, de manera similar a como ocurre con la proteina natural proveniente de tuberculos. Las estrategias para la inclusion del fragmento nucleotidico sintetico en el gen de la esporamina se basaron fundamentalmente en las predicciones de estructura secundaria, de perfil hidrofilico y otras caracteristicas, tanto de la proteina nativa como de las variantes quimericas (Figura 2). Las principales diferencias radican en un ligero incremento del contenido de helices alfa, acompanado de una ligera disminucion en el contenido de regiones beta en las variantes modificadas en relacion con la secuencia de la proteina natural. Comparativamente entre las variantes modificadas no existen diferencias sustanciales en lo que concierne a los parametros contemplados en la prediccion, aunque existen diferencias en los sitios seleccionados para la insercion. Para la variante pESS1, la diferencia en estructura secundaria antes mencionada es mas notable en la region entre los aminoacidos 100 y 200, mientras que en pESB2 se encuentra hacia la region comprendida entre los aminoacidos 200 y 285, aproximadamente. El perfil hidrofilico muestra un comportamiento similar entre la proteina codificada por el gen estructural y las variantes derivadas de ella. En estas ultimas se puede observar un desplazamiento del patron mostrado precisamente a partir de los aminoacidos codificados por el fragmento de ADN sintetico insertado.
La diferencia en talla de aproximadamente unos 10 KDa mas (Tabla 1) que poseen las variantes geneticas en relacion con la esporamina natural, es un aspecto que se tuvo en cuenta desde el diseno de las estrategias de modificacion contemplando la inclusion de un fragmento de ADN en la secuencia del gen estructural para la proteina. En cuanto a la composicion aminoacidica, pueden esperarse incrementos muy notables en el contenido de Lys, Met y Trp en las variantes en relacion con la esporamina natural, mientras permanece casi invariable la proporcion de los restantes aminoacidos. Este analisis permite suponer que las variantes pESS1 y pESB2 dan lugar a proteinas de mayor calidad nutricional teniendo en cuenta la composicion de aminoacidos esenciales. Los resultados de la secuenciacion de los clones pESS1 y pESB2 coincidieron con los patrones esperados. Es decir, el fragmento oligonucleotidico sintetico para el caso de pESS1 quedo incluido en la region mediana del gen estructural sin alterar el marco de lectura. De igual modo sucedio con el pESB2, pero insertado proximo a la region 3' del gen. Con los plasmidos recombinantes pETS1 y pETB2, portadores de las variantes quimericas de la esporamina, se transformaron cepas de E. coli y se detecto su expresion por Western blot (Figura 3). Las lineas 3 y 4 muestran las bandas correspondientes a las variantes pETS1 y pETB2, las cuales se observan a una talla aproximada de 37 KDa. De forma similar a lo descrito para la expresion de pES, al compararlas con los valores que aparecen en la Tabla 1, estas migran, unos 4 KDa por encima de lo previsto, para la proteina no procesada y unos 8 KDa mas en relacion con la prediccion de talla para la proteina madura.
Dada esta similitud de comportamiento en electroforesis pudiera inferirse que en las variantes, a pesar de la insercion del fragmento sintetico, la proteina quimerica ha conservado su capacidad de formar puentes disulfuros en este sistema bacteriano. En la linea 1, la esporamina natural purificada de tuberculos de boniato, presenta dos bandas muy proximas que inmunorreaccionan con el anticuerpo policlonal utilizado. Este comportamiento ha sido reportado (6) cuando no se utilizan condiciones extremas de desnaturalizacion. Los atributos que muestran las construcciones obtenidas, en especial su secuencia y expresion en E. coli, permiten predecir su posible utilizacion en estrategias para el incremento de la calidad nutricional del boniato, asi como de otros cultivos cuyas limitaciones esten originadas por deficiencias en el contenido de los aminoacidos Lys, Met y Trp. References 1. Walter WM Jr, Collins W, Purcell AE. Sweet potato protein. J Agr Food Chem 1984;32:695-699. 2. Ensminger AH, Ensminger ME, Konlande JE, Robson JRK. (Ed.) (1995). The concise encyclopedia of foods and nutrition. 1995 CRC Press, Inc.:1001. 3. Jones DB, Gersdorff CEF. Ipomoein, a globulin from sweet potatoes, Ipomoea batatas. Isolation of a secondary protein derived from ipomoein by enzymic action. Journal of Biological Chemistry 1931;93:119-126. 4. Varon D, Collins W. Ipomoein is the major soluble protein of sweet potato storage roots. HortScience 1989;24(5):829- 830. 5. Li H, Oba K. Major soluble proteins of sweet potato roots and changes in proteins after cutting, infection, or storage. Agric Biol Chem 1985;49(3):737-744. 6. Maeshima M, Sasaki T, Asahi T. Characterization of major proteins in sweet potato tuberous roots. Phytochemistry 1985;24(9):1899-1902. 7. Hattori T, Nakagawa T, Maeshima M, Nakamura K, Asahi T. Molecular cloning and nucleotide sequence of cDNA for sporamin, the major soluble protein of sweet potato tuberous roots. Plant Molecular Biology 1985;5:313-320. 8. Murakami S, Hattori T, Nakamura K. Structural differences in full-length cDNAs for two classes of sporamin, the major soluble protein of sweet potato tuberous roots. Plant Molecular Biology 1986;7:343-355. 9. Hattori T, Ichihara S, Nakamura K. Processing of a plant vacuolar protein precursor in vitro. European Journal of Biochemistry 1987;166:533-538. 10. Hattori T, Nakamura K. Genes coding for the major tuberous root protein of sweet potato: Identification of putative regulatory sequence in the 5' upstream region. Plant Molecular Biology 1988;11:417-426. 11. Hattori T, Yoshida N, Nakamura K. Structural relationship among the members of a multigene family coding for the sweet potato tuberous root storage protein. Plant Molecular Biology 1989; 13:563-572. 12. Laemmli UK. Cleavage of structural proteins during the assembly of the head of bacteriophage T4. Nature 1970;227:680- 685. 13. Harlow E, Lane O. (Ed.). Antibodies. A Laboratory Manual. Cold Spring Harbor Laboratory. N.Y. 1988. 14. Sambrook J, Fritsch EF, Maniatis T. Molecular cloning. A Laboratory Manual. 2nd ed. Cold Spring Harbor Laboratory, Cold Spring Harbor, N.Y. 1989. 15. Dellaporta SL, Wood J, Hicks B. A plant DNA minipreparation: Version II. Plant Molecular Biology Reporter 1983; 1:19-21. 16. Goyenechea B, Moran R, Gutierrez C, de la Riva G, Perez S. Pesquisaje de plantas transgenicas por reaccion en cadena de la polimerasa. Biotecnologia Aplicada 199;8(2):237-241. 17. Saiki RK, Erlich HA. Genome Analysis, A Practical Approach. Davies KE (Ed.). Oxford. U.K. 1988. 18. Yang MS, Espinoza NO, Nagpala PG, Dodds JH, White FF, Schnorr KL, Jaynes JM. Expression of a synthetic gene for improved protein quality in transformed potato plants. Plant Science 1989;64:99-111. 19. Lowry OH, Rosembrough NJ, Farr AL, Randal RJ. Protein measurement with the Folin Phenol reagent. J Biol Chem 1951;193:265-269. 20. Marck C. "DNA Strider": a "C" program for the fast analysis of DNA and protein sequences on the Apple Macintosh family of computers. Nucl Acid Res 1988;16:829-836. 21. Studier FW, Rosenberg AH, Dunn JJ, Dubendorff JW. Use of T7 RNA Polymerase to direct the expression of cloned genes. Methods Enzymology 1990;185. 22. Tabor S, Richardson CC. A bacteriophage T7 RNA polymerase/promoter system for controlled exclusive expression of specific genes. Proc Natl Acad Sci USA 1985;84:4767- 4771. 23. Varadarajan GS, Prakash CS. A rapid and efficient method for the extraction of total DNA from the sweet potato and its related species. Plant Molecular Biology Reporter 1991;9(1):6- 12. Copyright 1996 Elfos Scientiae
The following images related to this document are available:Photo images[ba96103c.jpg]Line drawing images[ba96103b.gif] [ba96103a.gif] |
| |||||||||

{kind=link}
{kind=link}
{kind=link}