 |
| About Bioline | All Journals | Testimonials | Membership | News |
|
||||||
|
||||||
Biotecnología Aplicada 1999;16:261-263 Uso de información previa en los ensayos clínicos aleatorizados con respuesta binaria Jorge Bacallao,1 Josefina Lugo2 1 Dpto. Computación y Biometría. Instituto Superior de Ciencias Médicas. Calle 146 No. 3102, La Habana 11600, Cuba. E-mail: bacallao@comput.giron.sld.cu 2 Dpto. Ensayos Clínicos. Instituto Nacional de Oncología y Radiobiología. Ciudad de La Habana, Cuba. Recibido en septiembre de 1998. Aprobado en mayo de 1999. Code Number:BA99044 RESUMEN Cuando se prueba un nuevo medicamento, se plantea el problema técnico y ético de incorporar el conocimiento procedente de ensayos previos, a partir de la realización de algún metaanálisis o simplemente de la apreciación subjetiva del investigador. En este artículo se propone un método no bayesiano basado en la distribución beta-binomial, que es aplicable en ensayos clínicos de medicamentos o tratamientos cuando la respuesta viene dada por una variable dicotómica (mejoría-no mejoría). La propuesta incluye la modelación del conocimiento previo a través de la distribución beta, tanto en la evaluación de la toxicidad como de la eficacia, y una prueba estadística de la eficacia basada en un parámetro de la distribución beta-binomial. Palabras claves: distribución beta-binomial, ensayos clínicos, métodos no bayesianos, respuesta binaria ABSTRACT Use of prior Knowledge in Randomized Clinical Trials with a Binary Response Variable. When testing a new drug, the researcher faces the ethical and technical problem of incorporating the existing knowledge derived from previous trials, from a meta-analysis or simply from his subjective judgement. This paper proposes a non-Bayesian method based on the beta-binomial distribution, which can be used in the clinical trial of a drug or treatment when the response variable is dichotomous. The method consists in the modeling of the previous knowledge by means of the beta distribution in the assessment of both toxicity and efficacy, and a statistical test of efficacy, which depends on a parameter of the beta-binomial distribution. Keywords: beta-binomial distribution, binary response, clinical trials, non-Bayesian methods Introducción Cuando se prueba un medicamento o un tratamiento en relación con su toxicidad o su efectividad, es frecuente que el investigador posea cierto nivel de información acerca de la respuesta de los sujetos que reciben el placebo. En los ensayos clínicos controlados raras veces se utiliza dicha información al optar, por ejemplo, por una prueba de comparación de las proporciones de respuesta entre sujetos tratados y no tratados, que toma en cuenta solamente lo que sucede a los casos de la muestra en uno y otro grupo, y se desentiende de toda la información previa [1]. Desde el punto de vista ético, esta opción tan común puede ser criticable, por el claro hecho de que no tiene las mismas consecuencias ni la misma interpretación, una diferencia fija entre proporciones, cuando éstas están en el rango de 0,8 a 0,9, que cuando están en el rango de 0,1 a 0,2. El problema puede plantearse en un contexto bayesiano si se dispone de información previa de otros ensayos similares, que permitiera hacer conjeturas razonables acerca de la distribución de la diferencia de las proporciones [2]. En el caso relativamente más frecuente en que sólo existe información sobre la frecuencia relativa de respuesta en sujetos no expuestos al principio activo del medicamento, el enfoque de este trabajo constituye una buena alternativa. Formalmente: Sea N el número de sujetos disponibles para el ensayo clínico, de los cuales N1 son asignados al grupo experimental y N2 al grupo control (N = N1 + N2). Supongamos que al final del ensayo cada sujeto pueda ser clasificado como "respondedor" o "no respondedor", y que el criterio de comparación sea la diferencia entre las probabilidades de respuesta de los dos grupos. Sea p la probabilidad de respuesta de un sujeto en el grupo placebo. En lugar de interpretar a p como un parámetro, considere que se trata de una variable aleatoria que puede variar en el tiempo y también de un contexto a otro. Dado p, se espera que, como promedio, una proporción p de sujetos del grupo experimental responda aun sin haber estado expuesta al principio activo. Por consiguiente, existirá una proporción 1 - p que puede responder al efecto real del tratamiento. De los que pueden responder, suponga que realmente responde una fracción d. Por lo tanto, dado p, la probabilidad de respuesta para un sujeto en el grupo experimental es p + (1 - p)d. Desde el punto de vista estadístico, el problema ha quedado reducido a hacer inferencias acerca de d. Observe que mientras mayor sea d, mayor será la efectividad del tratamiento. Por ejemplo, si d = 0, la proporción de respondedores será igual en los dos grupos, mientras que si d = 1, en el grupo experimental 100% de los sujetos será respondedor. Métodos Modelación probabilística de la información previa Se considerarán dos casos: 1) cuando la información está disponible sólo en términos de una conjetura subjetiva del investigador o del monitor del ensayo, y 2) cuando existen datos estadísticos sobre sujetos no tratados. Se considerarán, igualmente, dos tipos de respuesta: la toxicidad y la efectividad. En el primer caso, la muestra está formada por sujetos sanos que son clasificados como respondedores si enferman durante el ensayo, lo cual ocurre con una probabilidad p en el grupo placebo. En tal caso, es razonable suponer que la función de densidad de p es continua, acotada y decreciente en el intervalo [0; 1], y que alcanza su máximo en 0, lo cual equivale a suponer que lo más probable es encontrar una proporción baja de sujetos que enferman en el grupo placebo, y que las proporciones más altas son cada vez menos probables. La distribución beta con parámetros a = 1 y b > 1 satisface estas propiedades [3–5]. El problema estadístico, en este caso, se resume a estimar b. Si a partir de experiencias previas o de la revisión de la literatura el investigador puede afirmar, por ejemplo, que 90% de las veces p es menor que 0,10, entonces (Recuadro): Si se resuelve esta ecuación para b: Si es posible estimar aproximadamente el valor de p, digamos, por ejmplo, p = 0,07, entonces se puede estimar b a partir de la relación: de donde b = 13,29 En el segundo caso, la muestra está compuesta por pacientes que son considerados respondedores si mejoran durante el estudio. En esta situación, p es la probabilidad de que un paciente mejore simplemente por efecto placebo, y es plausible suponer que su función de densidad sea continua, que valga 0 en los extremos del intervalo [0; 1] y que alcance un máximo en el interior de dicho intervalo. De nuevo, la distribución beta satisface estas condiciones y el problema estadístico se convierte en la estimación de a y b. Si se trata de una enfermedad que no tiene remisión espontánea, entonces se puede suponer que a = 1 y se pueden aplicar los resultados anteriores. Si el investigador puede estimar aproximadamente la media y la varianza de p, a y b pueden obtenerse a partir de las relaciones siguientes: donde: m : media de ps2 : varianza de p (Recuadro)Si se asume, por ejemplo, que la probabilidad de respuesta en los pacientes tratados es mayor que en los no tratados, pero que todos los valores de p son igualmente probables, el problema se simplifica considerablemente porque se reduce a una distribución beta con parámetros a = 1 y b = 1 (equivalente a la distribución uniforme). En este caso el problema se simplifica, pero también se trivializa, porque da lugar a una distribución a priori no informativa y queda prácticamente reducido al caso clásico de una comparación de proporciones sin hacer uso de información previa. Suponga ahora que el investigador tiene acceso a k estudios independientes en los que los eventos clave (end-point) son iguales a los del ensayo clínico en cuestión. Suponga, además, que los grupos de placebo son similares en todos los ensayos previos y similares al presente ensayo, en el sentido de que la distribución de p no cambia de un ensayo a otro. Si Mi y Xi denotan el número de sujetos y el número de éstos que son respondedores, respectivamente, en el grupo placebo del i-ésimo estudio, entonces la distribución de Xi es beta-binomial [6] cuya función de densidad está dada por: donde: C(Mi;Xi): número de combinaciones de Mi en Xi Ahora, la media y la varianza muestrales de las Xi pueden ser utilizados para estimar los parámetros de la distribución de p. Así pues, si se denota: a la media y la varianza muestrales de las Xi, se puede demostrar [3–5] que: Para estimar a y b, se sustituyen en la ecuación IV los valores esperados por los valores de la media y la varianza muestrales de Xi. Estas estimaciones son muy sencillas y si los valores de Mi son grandes, también pueden ser bastante precisas. Inferencias estadísticas sobre d A partir del enfoque esbozado en la introducción, está claro que la hipótesis de que el fármaco es efectivo equivale a la hipótesis de que d > 0. Así pues, el problema de prueba de hipótesis H0 : d = 0 vs. HA : d > 0 es idéntico al problema H0 : p1 = p2 vs. HA : p1 > p2, en el que p1 y p2 representan, respectivamente, las proporciones de respondedores en los grupos experimental y placebo. Por otra parte, se necesita encontrar un estimador para d. Para este último problema, se recurrirá al conocido principio de la máxima verosimilitud, y para el problema de prueba de hipótesis, a la distribución empírica de la razón de las verosimilitudes [5]. Suponga que en un ensayo clínico se aleatorizan N sujetos, de los cuales N1 quedan asignados al grupo del tratamiento y N2 = N – N1 al grupo placebo. Sean X1 y X2 los números respectivos de respondedores. Dado p, la distribución de X1 y X2 es binomial con sus respectivos parámetros [N1;p + (1 – p)d] y [N2;p]. Si recordamos que p es una variable aleatoria con distribución beta, entonces la distribución conjunta de X1, X2 y p está dada por: donde, para (j = 0, 1, 2,... x1): Para obtener el estimador máximo-verosímil, lo que queda es hallar la derivada de la función de verosimilitud con respecto a d, igualar a cero y resolver la ecuación resultante. Formalmente, resuelva: Por otra parte, el método de la razón de verosimilitudes para el problema de prueba de hipótesis H0 : d = 0 vs. HA : d > 0, consiste en calcular el cociente:§ donde d* representa un valor fijo dado de la alternativa. Por ejemplo, es fácil ver que f(x1,x2;d = 0) = CN1 y que, si d = 1, entonces x1 = N1 y: Por consiguiente, si denominamos RV a la razón de verosimilitudes, resulta que cuando d = 1: En general, una vez que hayamos estimado d (sea d* el estimado), la razón de verosimilitudes se convierte en: Debido a que habitualmente es razonable suponer que el tratamiento es al menos tan efectivo como el placebo, RV es menor que 1. Por lo tanto es común trabajar, en lugar de RV, con –2log(RV), que por la razón anterior suele ser positivo. A partir de la ecuación V hay dos caminos posibles: el camino clásico sería tratar de encontrar la distribución de –2log(RV) o construir su distribución empírica por simulación para diferentes valores de a, b, N1, N2, x1 y x2. Hallar la distribución exacta o asintótica de –2log(RV) puede plantear un problema teórico muy complejo: construir la distribución empírica y, a partir de ella, una región crítica para el problema de prueba de hipótesis H0 : d = 0 vs HA : d > 0, es simple en teoría, pero complejo en la computadora. El otro camino sería resolver la ecuación V para los valores de d que hacen a RV < 1. Este sería el conjunto de valores más verosímiles o con mejor apoyo empírico que la nulidad. El conjunto solución de la desigualdad RV < 1 podría hallarse por métodos numéricos de solución de sistemas no lineales como, por ejemplo, el método de Newton-Raphson [7]. Esta alternativa no es, en rigor, una solución al problema de prueba de hipótesis H0 : d = 0 vs. HA : d > 0, sino al problema más general de determinar el conjunto de valores del parámetro d mejor apoyados por evidencias que la hipótesis nula de que el medicamento no es eficaz. Discusión En los ensayos clínicos en que el suceso clave (end-point) es una variable de Bernoulli (mejoría-no mejoría, muerte-sobrevida, remisión total-recidiva), suelen aplicarse las técnicas clásicas de comparación de proporciones, que no toman en cuenta de forma explícita la información previa sobre los pacientes que reciben placebo (no tratados). Esta opción técnica también tiene, sin dudas, implicaciones éticas (al menos desde la óptica de una ética social [1]), porque al ignorar la información previa, puede restarle poder estadístico a un procedimiento para detectar efectos potencialmente importantes. Las dos soluciones más naturales para este problema serían la realización de un metaanálisis [8] o el empleo de la estadística bayesiana en la forma de una distribución a priori para la diferencia entre las proporciones de respuesta entre uno y otro grupo. Si se dispone de información sobre un número suficiente de ensayos previos, tales soluciones son, sin dudas, las mejores alternativas, aun a pesar de la subjetividad en la elección de una distribución a priori y de los conocidos problemas de sesgo en la ejecución de un metaanálisis. Si se trata, por el contrario, de una prueba que se realiza por primera vez, este enfoque tiene ventajas indudables. Sus aportes básicos son dos: • la modelación del conocimiento previo acerca de la frecuencia relativa de respuesta espontánea o a la utilización de una terapia tradicional • la posibilidad de hacer inferencias estadísticas (estimación puntual, estimación del conjunto más verosímil que la nulidad o prueba de hipótesis clásica) acerca de un parámetro de una distribución (beta-binomial), sobre el que ya se ha incorporado explícitamente la información previa. Referencias
§El criterio del cociente de verosimilitudes fue propuesto por Neyman y Pearson en 1928. En su versión original [5], el denominador es el supremo de la función de verosimilitud para todos los posibles valores del parámetro d. Cuando se trabaja en forma habitual con la distribución asintótica de -2log(RV), que en muchos casos resulta ser c2, se puede poner a prueba la hipótesis de que d = d0. Bajo el enfoque de este artículo, RV se utiliza sólo para medir cuánto más verosímil es d = 0 en comparación con un valor d = d* de efectividad, para las observaciones x1 y x2. Copyright Elfos Scientiae 1999 The following images related to this document are available:Photo images[ba99044j.jpg] [ba99044h.jpg] [ba99044b.jpg] [ba99044o.jpg] [ba99044m.jpg] [ba99044d.jpg] [ba99044l.jpg] [ba99044k.jpg] [ba99044g.jpg] [ba99044i.jpg] [ba99044c.jpg] [ba99044n.jpg] [ba99044e.jpg] [ba99044f.jpg]Line drawing images[ba99044a.gif] |
| |||||||||

{kind=link}
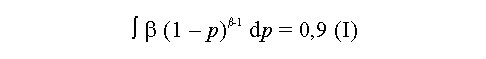{kind=link}
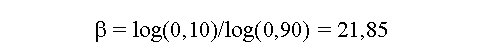{kind=link}
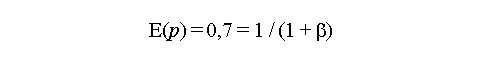{kind=link}
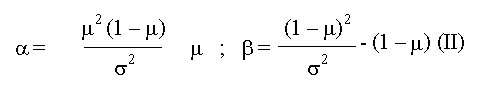{kind=link}
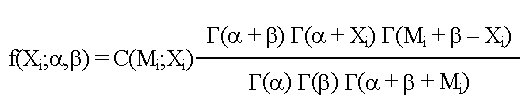{kind=link}
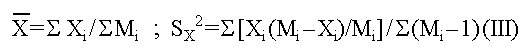{kind=link}
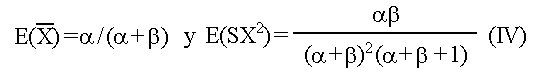{kind=link}
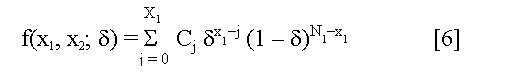{kind=link}
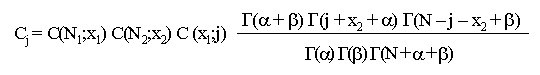{kind=link}
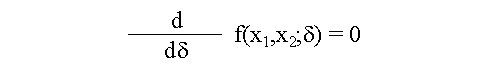{kind=link}
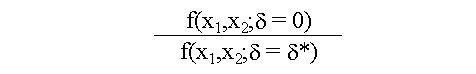{kind=link}
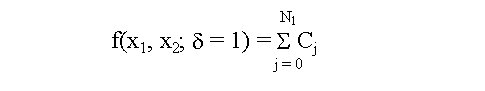{kind=link}
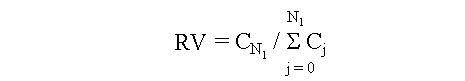{kind=link}
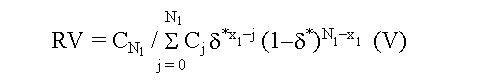{kind=link}