 |
| About Bioline | All Journals | Testimonials | Membership | News |
|
||||||
|
||||||
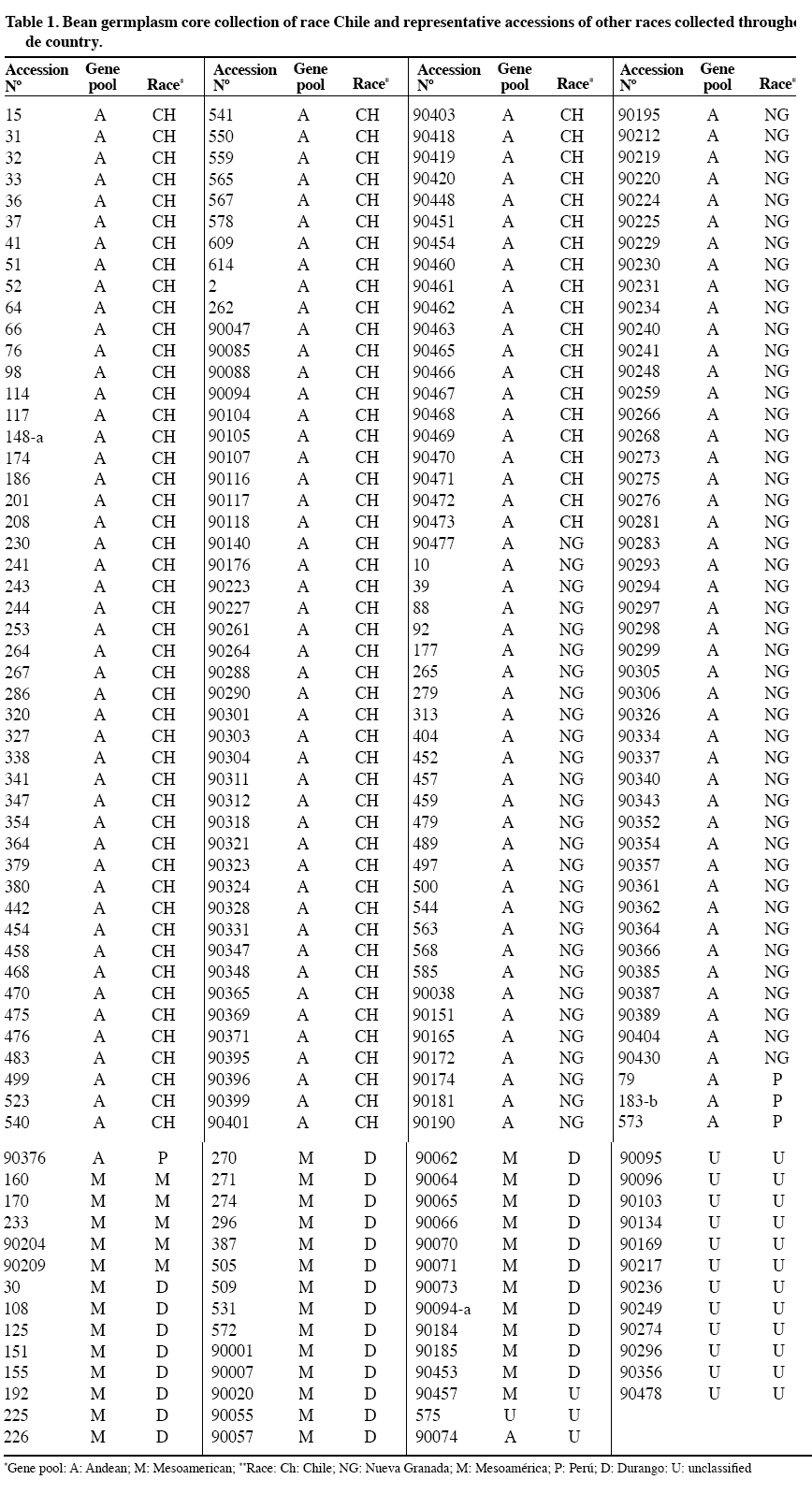
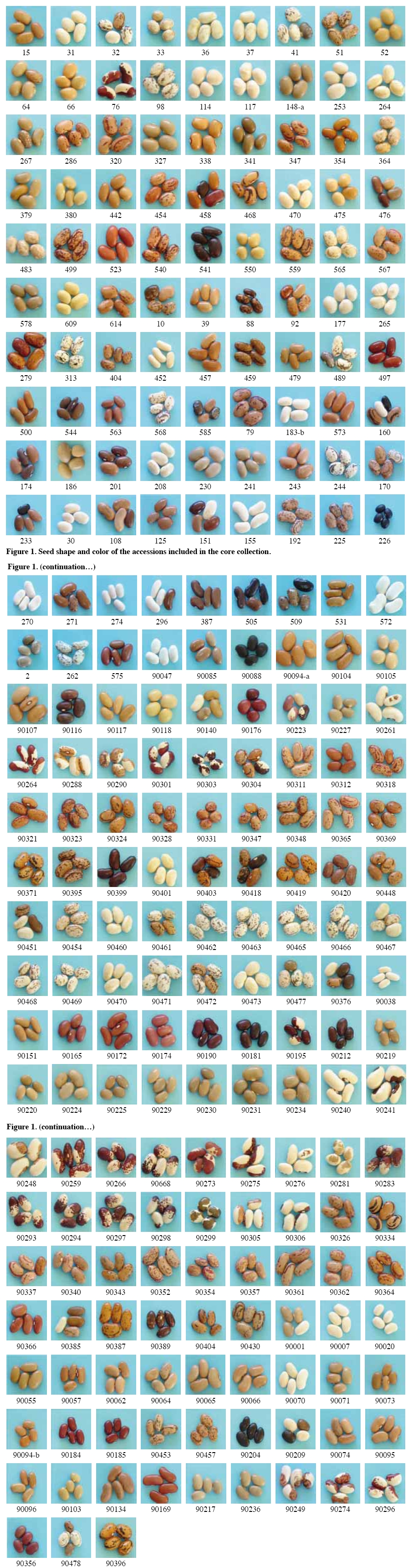
Chilean Journal of Agricultural Research, Vol. 70, No. 1, Jan-Mar, 2010, pp. 3-15 RESEARCH Selection of a representative core collection from the Chilean common bean germplasm Selección de una colección núcleo representativa del germoplasma chileno de porotos Mario Paredes C.[1]*, Viviana Becerra V.1, Juan Tay U.1, Matthew W. Blair[2], and Gabriel Bascur B.[3] [1]Instituto de
Investigaciones Agropecuarias INIA, Casilla 426, Chillán, Chile. *Corresponding
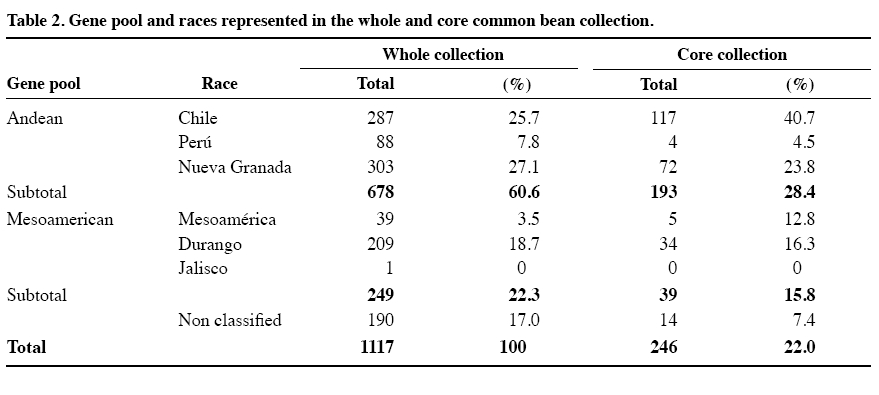
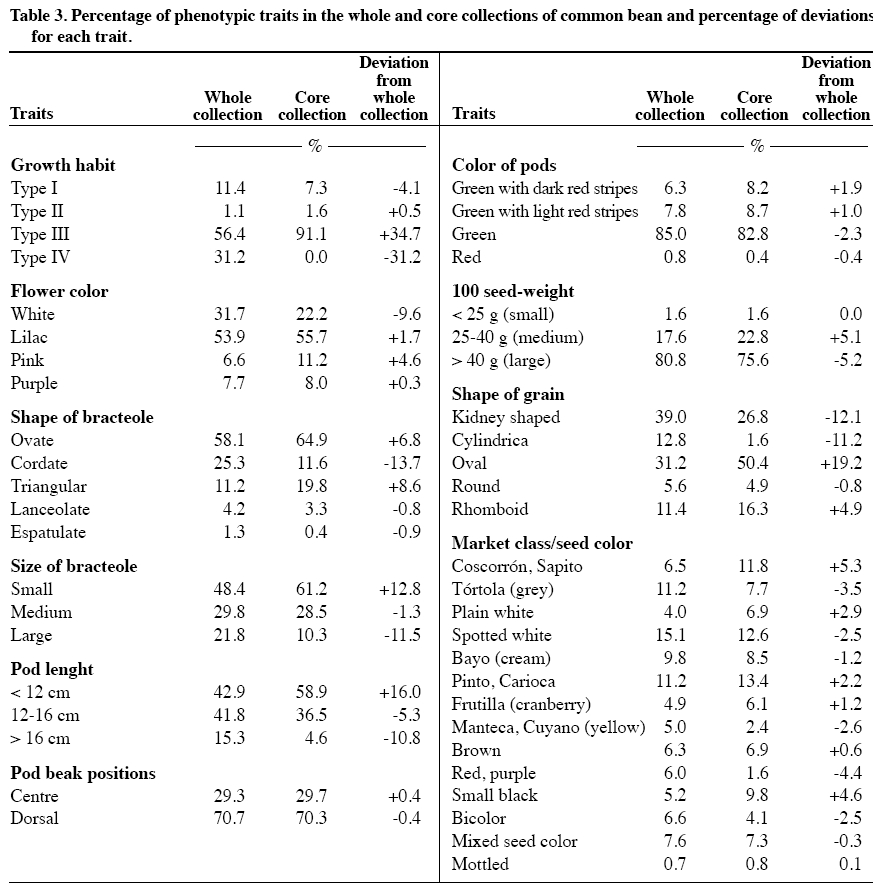
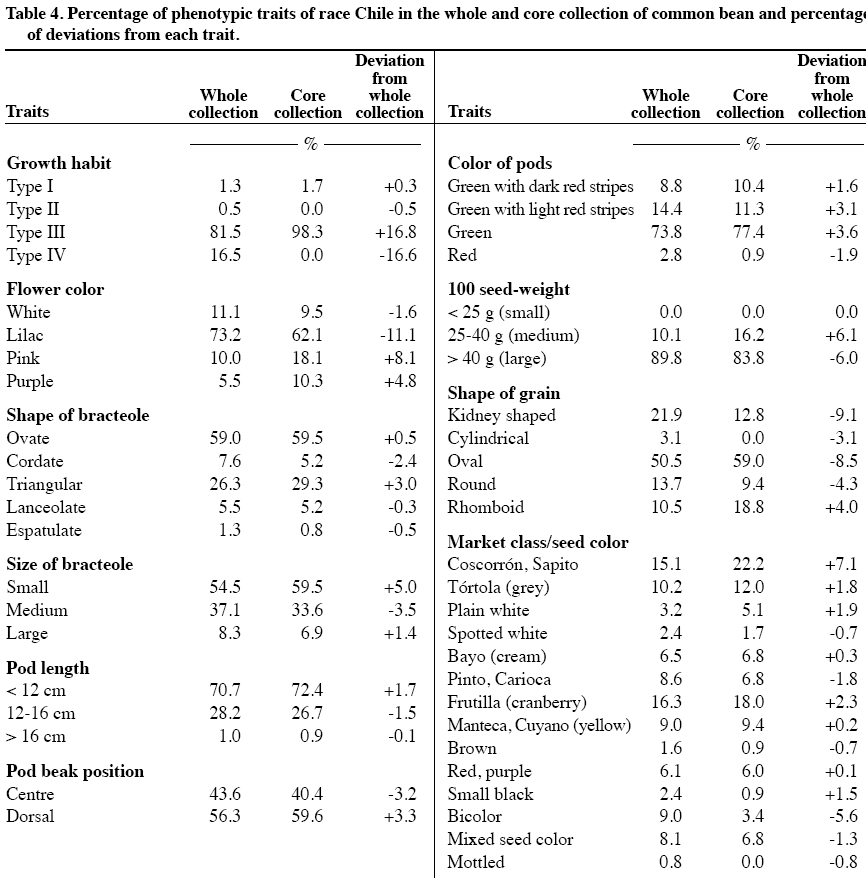
author (mparedes@inia.cl). Received: 16 March 2009. Code Number: cj10001 ABSTRACT Race Chile is an important component of the genetic structure of the common bean (Phaseolus vulgaris L.). The germplasm bank of the Instituto de Investigaciones Agropecuarias INIA contains 1200 accessions distributed mainly into two Active Working Germplasm Banks at INIA La Platina (Santiago) and at INIA Quilamapu (Chillán) and also the Germplasm Base Bank at INIA Intihuasi (La Serena). The Chilean collection possesses accessions collected throughout the country. One way to study and use the germplasm stored at the Seed Banks is the formation of a core collection. The objectives of this work were: a) To establish a common bean core collection with the germplasm collected throughout the country, and b) to evaluate its representatives based on phenotypic data and to compare with data from the whole collection. The results indicated that the Chilean base collection contained accessions belonging to the Andean and Mesoamerican gene pools and to genotypes belong to race Chile, Perú, Nueva Granada, Mesoamerica and Durango. The Chilean bean core collection consisted of 246 accessions. Comparison for several phenotypic traits data from 246 accessions from the whole and core collection indicated the genetic variation expressed for each trait in the whole collection was quite well represented in the core collection. This core collection will be very useful for further phenotypic and genetic characterization and to select accessions for the bean breeding program. Key words: phenotypic variability, bean gene pools, race Chile. RESUMEN La raza Chile es un componente importante de la estructura genética del germoplasma del poroto común (Phaseolus vulgaris L.). El Instituto de Investigaciones Agropecuarias, INIA, posee alrededor de 1200 accesiones almacenadas en los Bancos activos de Germoplasma en INIA La Platina (Santiago) e INIA Quilamapu (Chillán) y Banco Base en INIA Intihuasi (La Serena). Esta colección está formada por accesiones colectadas a través de todo el país. La formación de una colección núcleo se ha planteado como una forma de hacer un uso más eficiente del germoplasma almacenado en los Bancos de Germoplasma. Los objetivos de este trabajo fueron formar una colección núcleo de germoplasma de porotos, y evaluar su representatividad. La estrategia utilizada para formar la colección núcleo fue la estratificación de las accesiones de la colección base de acuerdo al acervo genético y raza, permitiendo que la mayor diversidad genética estuviera representada en esta nueva colección. Los resultados obtenidos indicaron que la colección base estaba formada por genotipos pertenecientes a los acervos genéticos Andino y Mesoamericano y a las razas cultivadas Chile, Perú, Nueva Granada, Mesoamérica y Durango. La colección núcleo estuvo formada por 246 accesiones, donde se dio mayor representatividad a las accesiones de la raza Chile. La comparación morfológica, fenológica y agronómica permitió determinar que la diversidad genética presente en la colección base estaba representada adecuadamente en la colección núcleo. Esta colección núcleo será de gran utilidad para futuros estudios de caracterización de este germoplasma y para seleccionar progenitores para el programa de mejoramiento genético de frejol. Palabras clave: variación fenotípica, acervos genéticos, raza Chile. INTRODUCTION In common bean (Phaseolus vulgaris L.) two main gene pools have been described. One center of domestication is located in Mesoamérica and the other in the Andes (Velásquez and Gepts, 1994; Tohme et al., 1996; Chacón et al., 2005; Kwak and Gepts, 2009). In addition to these two major gene pool centers, other regions have been mentioned as new possible secondary centers of domestication (Tohme et al., 1995; Beebe et al., 1997; Islam et al., 2001; Santalla et al., 2002). The Mesoamerican gene pool can be divided into three races: Mesoamérica, Durango and Jalisco, the Andean gene pool is represented by the Nueva Granada, Perú and Chile races (Singh et al., 1991). The establishment of ex situ germplasm collection has been the result of a global effort to conserve plant biodiversity. The centers of the Consultative Group on International Agricultural Research (CGIAR) maintain over 600000 accessions of plant species, and over six millions more are conserved in institutions around the world. The genotypic and phenotypic diversity maintained in the collections can be invaluable for breeding programs, but also for basic research such as evolution, gene expression, resistance to biotic and abiotic stress and other areas (Dudnik et al., 2001). On the other hand, Gómez et al. (2005) recommend both in situ and ex situ conservation methods in order to preserve landraces adaptation and to capture new and useful diversity present at in situ populations. The Chilean Instituto de Investigaciones Agropecuarias (INIA), in collaboration with the Centro de Agricultura Tropical (CIAT) and International Plant Genetic Resources Institute (IPGRI) carried out a germplasm collection of common bean in 1980. One copy of this collection is stored at CIAT and a second copy is conserved at INIA. In Chile, this germplasm has been multiplied and stored at the Base Genetic Seed Bank located in INIA Intihuasi (Vicuña, 30º01’ S lat) and in the Active Gene Bank at INIA Quilamapu (Chillán, 36º36’ S lat) and La Platina (Santiago, 33º26’ S lat). In addition, two explorations carried out in the Northern, mainly Arica province (Paredes and Becerra, 2000, data not published) and in the Central part of the country, from Chillán city to Cerro La Campana (32º55’ S lat) have confirmed the absence of wild beans in the country (Paredes, Becerra, Debouck, and Matus, 1999, data not published). On the other hand, INIA has a long history on bean breeding and has released several cultivars (Paredes et al., 1989; Paredes, 1994) and currently is the only active bean breeding in the country. A phenotypic evaluation carried out at two locations, Chillán and Santiago, indicated that from the total collected germplasm only 24% of the genotypes represented the typical traits of race Chile (Bascur and Tay, 2005). The first molecular analysis of a reduced number of accessions of the race Chile using restriction fragment length polymorphisms (RFLPs) markers indicated that the level of genetic diversity was low (Velasquez and Gepts, 1994). Later on, these results were confirmed by using a larger sample of Chilean germplasm (Vera et al., 1999), using random amplified polymorphic DNA (RAPD). Another genetic diversity study of 95 accessions from Chilean germplasm detected a high level of introgressions between this material and the Mesoamerican genotypes, using phaseolin and isozymes as genetic markers. The genetic analysis also detects a rare polymorphism for some allozyme data (Paredes and Gepts, 1995a) and a preferential transmission of the Mesoamerican alleles to Andean germplasm (Paredes and Gepts, 1995b). The high level of introgression in the Chilean germplasm was not detected by Johns et al. (1997) using RAPDs and different set of accessions. At the same time, Johns et al. (1997) and Blair et al. (2007) suggested that Chilean germplasm is composed by germplasm coming from the Andean and Mesoamerican gene pool. Also, typical race Chile genotypes are often found at higher latitudes in Turkey, Iran and China as well (Beebe et al., 2001). To obtain a better understanding of the Chilean germplasm we propose to form and evaluate a core collection. The concept of active core collections and core collections was proposed by Harlan (1972) and Frankel and Brown (1984), respectively. The aim of the core collection is to promote the use of the germplasm and facilitating the study of its genetic diversity. A core collection is a subset of the whole collection that represents the genetic diversity of a crop species with minimum repetitiveness (Brown, 1989a). The core collection could serve as a working collection to be extensively examined; the accession excluded from the core collection will still be retained as part of the reserve collection. The establishment of the core collection involves two main steps. The first one includes the characterization of the genetic diversity of a species and the second one, the choice of accessions to be included in the core collection based on phenotypic/molecular genetic diversity data. The core collection idea has been applied in several legumes crop such as dry beans (Tohme et al., 1995; Gepts, 1995; 2000; Beebe et al., 1997; 2001; Rodiño et al., 2003), alfalfa (Diwan et al., 1994), peanut (Holbrook et al., 1993), lentils (Erskine y Muehlbauer, 1991), rice (Yan et al., 2007) and to identify sources of resistance for Sclerotinia sclerotiorum (Lib.) de Bary (Miklas et al., 1999) in dry beans. Despite of the importance of the common bean in Chile, this germplasm has received little attention and only few accessions have been analyzed. The objectives of this work were to establish a Chilean bean core collection from germplasm collected throughout the country, and to evaluate its representativeness compared with the whole collection. MATERIALS AND METHODS Whole collection In 1980, the Chilean bean collection was composed of 1239 accessions collected from 207 locations in the country (18º28’ to 42º19’ S lat). This germplasm includes genotypes from Andean and Mesoamerican gene pools and races Chile, Nueva Granada, Perú, Mesoamérica, and Durango (S. Singh, data not published; Bascur and Tay, 2005). At the moment of this work approximately 1100 accessions were available for sampling, the rest of the genotypes did not have enough seed and they were in process of multiplication. Core collection sample procedure The procedure used to establish the Chilean bean core collection was based on the concept that preexisting information about the collection can be used to stratify the accessions. The entire germplasm collection was then stratified by agroecological (geographic) distributions and genetic structure as well as the morphological and phenological data available on the germplasm collected throughout the country. Therefore, this sampling strategy is both systematic and random because no pre-designation of accessions was imposed and the accessions selected for a particular group represent one of the possible randomization events. The core collection was formed taking into account previous hierarchical statistical analysis (data not published) that grouped the germplasm. The sampling collection included the following steps: First, it was decided that 20% of the whole would represent the working collection; second, a proportional method adjusted by the relative importance of the common bean in each agroecological (geographic) area was used to select the accessions; third, a new representative sample was taken from the previous stratification of the genotypes by gene pool, race, market classes, and phenotypic traits data. Finally, a random selection of genotypes within each category was done. The number of genotypes selected from each category to form the core collection was proportional to the size of the group and their geographical distribution in the whole collection. This approach ensures that each group is represented in the working collection according to its frequency in the whole collection. The agroecological conditions included genotypes collected in the northern, central and southern part of the country, as well as, genotypes from the costal and interior land (Bascur and Tay, 2005). Each geographical area represented different soil and climatic conditions. The genetic structure of the germplasm was categorized by gene pool (Andean and Mesoamerican) and by cultivated races: Race Chile, Perú and Nueva Granada in the Andes and Race Mesoamérica and Durango in the Mesoamerican gene pool. The following traits were used in the selection scheme for the working collection: growth habit, leaflet length, flower color, size and shape of bracteole, pod length and position, 100-seed weight, seed shape, and seed market classes. RESULTS AND DISCUSSION Whole Chilean common bean collection A higher percentage of Andean germplasm (60.7%) compared with the Mesoamerican materials (22.3%) was collected throughout the country. Thus, an analysis per race of the whole collection indicated that the genotypes classified as race Chile represented 25.7%, race Perú 7.8%, Nueva Granada 27.1%, Mesoamérica 3.5%, Durango 18.7% and only one genotype classified as race Jalisco was collected. This situation indicated a higher agronomic adaptation, farmer´s preference for the Andean materials in the country, as well as, the high demand of the Chilean consumers and the international trade. The absence of genotypes from race Jalisco may be due to the fact that they represent mostly climbing cultivars of the southern, humid highland of Mexico and Central America and they are not adapted to the Chilean cropping system where the commercial cultivars belongs to type III, II and I. The low presence of genotypes from race Perú may due to similar reasons: Race Perú consists mainly of cultivars with climbing growth habit adapted to higher altitude even though there are some not climbing genotypes. Race Mesoamerica includes the determinate bush cultivars from the humid, hotter low land of Mexico, Central America and South America, represented in Chile mainly by the small blacks and navy bean seed market classes. Race Nueva Granada includes cultivars with determinate bush or indeterminate climbing growth habits adapted to moderate altitude. Race Chile and Durango present a similar phenotype, indeterminate semi-climber or prostrate growth habits, and medium-sized seeds with light pigmentation (Singh et al., 1991). It is postulated that this similar phenotypes may have resulted from convergence caused by selection for adaptation to arid environments in Northern Mexico and Chile (Gepts, 1995). Chilean common bean core collection There are several sampling strategies that can be applied. The strategies depend on the species, the composition of the collection, and the type of characters of interest. In this work, the common bean core collection is constituted by 246 genotypes (Table 1, Figure 1) which represented a 22% from the base collection (Bascur and Tay, 2005). Brown (1989a) proposed that a core collection should contain about 10% of the whole collection. This sampling procedure should result in about a 0.80% of the alleles that occur in the whole collection. Miklas et al. (1999) reported that a 10% is an adequate sample size to represent the genetic diversity of a whole collection in common beans. However, they had to reduce this sample size in 50% for practical reasons. On the other hand, Rodiño et al. (2003) established a bean core collection with a sample of 13% of the whole collection from the Iberian Peninsula. In peanut, Holbrook et al. (1993) utilized 11.2% accessions from the whole collection to form the core collection; in durum wheat Spagnoletti-Zeuli and Qualset (1993) a 16.6%, and in quinoa Ortiz et al. (1998) a 10%. There are also several factors to be taken into account to sample a whole population to select a core collection. In this work the sample procedure followed the general procedure suggested by Brown (1989a). The germplasm was sampled based on agroecological regions, genetic structure (gene pool, race) and on available morphological data. In this way, accessions from a wide geographical area will provide indirect evidence of diversity since accessions from the same origin can be assumed to share a larger portion of their gene pool (Peeters and Martinelli, 1989), the stratification for gene pool and race will contribute to the same purpose. To include the information of the characterization of the whole collection based on strongly inherited characters of agronomic importance also improved the identification of phenotypes clusters within those groups in the core collection. Stratification based on the identified clusters may improve the efficiency over simple random sampling (Spagnoletti-Zeuli and Qualset, 1993) and the number of accessions to be drawn should be proportional to the logarithm to the frequency of each group (Brown, 1989b) to avoid redundancy. Several sampling methods to select accessions for the core collection have been suggested, ranging from random sampling to stratify based on groups with sample size, constant, logarithmic or proportional to the group size (Erskine and Muehlbauer, 1991; Holbrook et al., 1993; Diwan et al., 1994; Skroch et al., 1998; Ortiz et al., 1998; Rodiño et al., 2003). Comparison between sampling methods have been tested (Spagnoletti-Zeuli and Qualset, 1993; Hu et al., 2000; Franco et al., 2006). For example, Spagnoletti Zeuli and Qualset (1993) comparing five sampling methods: random, random-systematic, stratified by country-of-origin, stratified by log frequency by country-of-origin, and stratified by canonical variables, concluded that first three methods produced samples representative of the whole collection, but the others two increase the frequencies from less represented country-of-origin for several traits. The multivariate analysis is extremely useful, but requires considerable data from the whole collection. They recommended that in absence of this complete set of information; the ecogeographic origin of the accessions may be used to establish a core collection. On the other hand, Hu et al. (2000) showed that core collections based on genotypic values retained larger genetic variability and had superior representatives than those based on phenotypic values. Since the main objective of this work was to establish a core (working) collection that represented the whole collection, a percentage of each type of germplasm was selected in the core collection (Table 1). Therefore, this core collection included a higher number of genotypes from the Andean genotypes (28.4%) compared with the Mesoamerican ones (15.8%). The same criteria were used to select the number of accession from each race (Table 2), with the exception of the race Chile. In this situation, the core collection included 40.7% of the germplasm present in the whole collection. After finishing the molecular characterization of this germplasm with microsatellites, we are planning to improve the representation of this working collection. Consistency of the core collection The size of the whole collection creates a serious problem with respect to seed increase, maintenance, evaluation and utilization in breeding programs. A possible solution to this problem is to establish a core collection. One major condition that must fulfill the core (working) collection is to represent the genetic variability of the whole (base) collection. The main reason for establishing a core collection is to provide easier access to the whole collection. Because it is representative of the genetic variability of the species, a screening of the core collection may result in the identification of accessions with the desired trait. The crucial aspect to establish a core collection is ensuring its representativeness of genetic diversity of the species. The genetic diversity in a species is not randomly distributed, but rather organized as gene pools, races, ecotypes (Tohme et al., 1995) and characterized by certain levels of both population differentiation and linkage disequilibrium (Brown, 1989a). One way to compare the representativeness of the working collection is to compare in this first step the phenotypic information available from both collections, such as growth habit, flower color, bracteole shape and size, pod length, position and size, 100-seed weight and shape and market classes (Table 3). This comparison will be further refined with molecular information. The analysis of both collections indicated that the core collection represented adequately the phenotypic variability of the base collection with one exception. The bean plant type III was over represented compared with type IV (Table 3). It was decided to place special emphasis on germplasm with growth habit I, II and III that could be used in the bean breeding program. One objective of the breeding program is to produce commercial dry bean cultivars with an upright growth habit to favor the mechanical harvesting of the bean crop. Consistency of phenotypic variability of race Chile within whole and working collection The comparison of the three types of germplasm indicates that the race Chile as a whole is well represented in the core collection (Table 4). Most of the traits of the race Chile are incorporated in the core collection with small differences compared to the base collection, with the exception of the over representation of type III growth habit as explained before. That means that the core collection represented the phenotypic variability of the base collection and the race Chile as well. According this information, most of the race Chilean germplasm possesses the following phenotypic characteristics: type III growth habit (81.5%), liliac flower (73.2%), ovate (59.0%) to triangular bracteole (26.3%), small (54.5%) to medium bracteole (37.1%), small (70.7%) to medium pod length (28.2%), green pod color (73.8%), large 100-seed weight (89.8%), with and ovate (50.5%) to kidney seed shape (21.9%) and composed of an array of market classes such as Coscorrón y Sapito (15%), Tórtola (10%), Manteca y Cuyanos (9.0%). Besides, race Chile germplasm is susceptible to Common, Yellow, Alfalfa and Cucumber mosaic virus and medium to late maturity. This description of the race Chile germplasm agrees with Singh et al. (1991) and Paredes (1994). CONCLUSIONS The preexisting information available about the whole collection allowed establishing a preliminary core collection of common bean collected in Chile. The information available allowed the stratification and random selection of the accessions considering the agroecological (geographic), genetic structure of the germplasm (gene pool and races) and phenotypic data. This collection includes 246 genotypes that belong to both major gene pools (Andean and Mesoamerican), and five out of six cultivated races (Chile, Perú, Nueva Granada, Mesoamerica and Durango) described previously. Only one accession classified as race Jalisco was identified among the whole collection, and was not included in this study. The comparison of the phenotypic data of both collections showed that the core collection include most of the variability present in the whole collection. ACKNOWLEDGEMENTS This work was funded by project FONDECYT N°1060185. The author wishes to thanks to Dr. Pedro León, Mrs. Erika Salazar and Filomena Venegas for providing seeds from the Germplasm Bank and to Mr. Alfonso Valenzuela and Mr. Pablo Gamboa for their field assistance. LITERATURE CITED
Copyright © 2010 - Universidade de Santa Cruz do Sul The following images related to this document are available:Photo images[cj10001f1.jpg] [cj10001t2.jpg] [cj10001t3.jpg] [cj10001t4.jpg] [cj10001t1.jpg] |
| |||||||||

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}