
|
Electronic Journal of Biotechnology
Universidad Católica de Valparaíso
ISSN: 0717-3458
Vol. 10, Num. 3, 2007, pp. 473 - 480
|
Untitled Document
Electronic Journal of Biotechnology, Vol. 10, No. 3, July 15, 2007, pg.
473 - 480
TECHNICAL NOTE
Isolation of simple sequence repeats from groundnut
Chuan Tang Wang*1, Xin Dao Yang2 , Dian Xu
Chen3 , Shan Lin Yu4 , Guang Zhen Liu5 , Yue
Yi Tang6 , Jian Zhi Xu7
1Shandong Peanut Research Institute Qingdao 266100 P
R China Tel: 86 532 87626662 Fax: 86 532 87626832 E-mail: chinapeanut@126.com
2Shandong Peanut Research InstituteQingdao 266100
P R China Tel: 86 532 88433679 Fax: 86 532 87626832 E-mail: smdkrdc@126.com
3Shandong Peanut Research InstituteQingdao 266100
P R China Tel: 86 532 87626723 Fax: 86 532 87626832 E-mail: Chenzhao126@sina.com
4Shandong Peanut Research InstituteQingdao 266100
P R China Tel: 86 532 87626830 Fax: 86 532 87626832 E-mail: rice407@sohu.com
5Shandong Peanut Research InstituteQingdao 266100
P R China Tel: 86 532 88411241 Fax: 86 532 88411241 E-mail: wangzhuo1995@126.com
6Shandong Peanut Research InstituteQingdao 266100
P R China Tel: 86 532 87626662 Fax: 86 532 87626832 E-mail: tangyueyi0597@sina.com
7Shandong Peanut Research Institute Qingdao 266100 P R China Tel:
86 532 88411707 Fax: 86 532 87626832 E-mail: Tsingtao2008@126.com
*Corresponding author
Financial support: The research was supported in part
by grants from China Natural Science Foundation (Grant No. 30300224), China
Ministry of Science and Technology (Grant No. 2002CCC03200, Grant No. 2006AA10A114),
and New and High Technology Innovation Foundation of Shandong Academy of Agricultural
Sciences (Grant No. 2006 YCX013).
Code Number: ej07046
Abstract
SSRs have proved to be the most powerful tool for variety
identification in groundnut of similar origin, and have much potential in genetic
and breeding studies. To facilitate SSR discovery in groundnut, we proposed
a highly simplified SSR isolation protocol based on multiple enzyme digestion/ligation,
mixed biotin-labeled probes and streptavidin coated magnetic beads hybridization
capture strategy. Of the 272 colonies randomly picked for sequencing, 119 were
found to have unique SSR inserts.
Keywords: groundnut, isolation, simple sequence repeat.
Abbreviations:
AFLP: amplified fragment length polymorphism
MW: molecular weight
PCR: polymerase chain reaction
SDS: sodium dodecyl sulfate
SSR: simple sequence repeat
Article
Groundnut or peanut (Arachis hypogaea L.), is an important
crop worldwide, distributed across the vast area in tropical, subtropical and
temperate zones. It is a valuable source of edible oil and protein for human
beings, and of fodder for livestock. In contrast to its apparent diversified
variations in traits, its genetic variations at molecular level as detected
by RAPD, RFLP, and SSR analysis, proved to be unexpectedly low (Halward
et al. 1993; Krishna et al. 2004). In that case, the genetic
linkage maps published were constructed using wild Arachis species (Halward
et al. 1993; Burow et al. 2001; Moretzsohn
et al. 2005).
Several workers (Hopkins et al. 1999; Gao
et al. 2003; Ferguson et al. 2004; Moretzsohn
et al. 2004) have reported groundnut SSR primers developed either based
on traditional library construction and screening or by exploiting an AFLP
pre-amplification protocol, with variable rate of success. Yang
et al. (2005) identified 24 new groundnut SSR-containing sequences by
means of GenBank inquiry. To facilitate SSR marker development in groundnut,
we presented a highly simplified SSR DNA isolation protocol with good results.
DNA was extracted from leaves of field-grown groundnut plants
of 24-3, a hybrid
derivative of Arachis hypogaea L. x A. glabrata Benth PI262801,
following a modified CTAB method as described earlier (Wang et
al. 2004). DNA digestion and ligation mixture (60 µl) containing
10 x NEBuffer4 6 µl, BSA (100x) 0.6 µl, groundnut genomic DNA 0.6 µg,
AP11/AP12 adaptor 15 pmol (AP11: 5'→3' CTCTTGCTTAGATCTGGACTA, AP12:5'→3'
pTAGTCCAGATCTAAGCAAGAGCACA), 10 mM ATP 6 µl, Dra I (NEB)
0.5 µl, Hae III (NEB) 1 µl, Rsa I (NEB) 0.5 µl, PshA
I (NEB) 0.5 µl and T4 DNA Ligase (NEB cat # M0202T) 2 µl, was
incubated at 37ºC overnight, and at 80ºC for 20 min to de-activate
the enzymes. Ten microliters of digestion and ligation product were pre-amplified
using 3 µl of AP11 primer (10 µM) in a volume of 50 µl, and
the PCR profile was 72ºC for
2 min, 94ºC for
2 min, and 10 cycles of 1 min at 94ºC,
1 min at 55ºC and 2 min at 72ºC, and a final extension
step of 72ºC for
10 min.
The hybridization mixture (30 µl), made up of 100 ng
of the pre-amplification product, 6XSSC, 0.1% SDS, and 200 ng each of 5' biotinylated (TA)30, (CA)20,
(GA)20, (AGA)15, (TGA)15, (ACA)15 (Sangon
Ltd), was subjected to 5 min of denaturation at 95ºC and 1 hr of re-naturation
at 60ºC.
Two hundred micrograms of streptavidin-coated paramagnetic beads (Promega),
previously equilibrated with 6xSSC for 3 times and 6xSSC, 0.1% SDS for 1 time,
were then added to the mixture. The mixture was incubated at 60ºC for 15 min with gentle
agitation at 5 min intervals. Liquid was removed using a magnetic separation
stand (Promega).
Beads were washed with gentle agitation with 300 µl of 6xSSC, 0.1% SDS
at room temperature for 15 min for 2 times, with pre-warmed 6xSSC, 0.1% SDS
(60ºC) at 60ºC for 15 min for 2 times,
and then with 300 µl of 6xSSC at room temperature for 15 min for 2 times
to remove SDS. After removal of final wash, captured DNAs were eluted from
the beads with addition of 200 µl of T.E preheated to 95ºC, gentle flicking of the
Eppendorf tube, and incubation at 95ºC for
10 min. With the aid of the magnetic stand, eluted DNAs in T.E buffer were
quickly transferred to an aseptic tube in ice bath, and then desalted at 4ºC using
a Millipore Microcon YM-100 column according to producer's recommendation.
The probes in the captured DNAs were also removed during this process, so were
the ssDNAs with MW lower than 300 nt.
The resultant DNAs were amplified using primer AP11, purified
and ligated into a pCF-T vector (Tiangen Biotech). Chemically competent
cells of TOPO 10 were utilized in heat-shock transformation. Length of inserts
was determined using a colony PCR procedure involving heat treatment of white
colonies with TTE buffer. DNA sequence was analyzed on an ABI 3730XL sequencer
using the M13 forward/reverse primer. After removal of the sequence of vector
and adaptor and exclusion of redundant sequences, SSRs in the inserts were
identified by exploiting the SSR Hunter and Tandem Repeat Finder search tools.
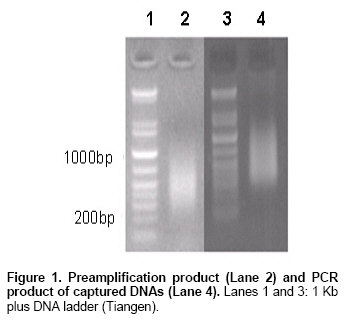
Agarose electrophoresis of pre-amplification product showed
that multiple enzyme digestion/ligation procedure produced DNA fragments of
expected size (200-around 1000 bp) (Figure
1). PCR product of captured DNAs was in the similar MW range (Figure
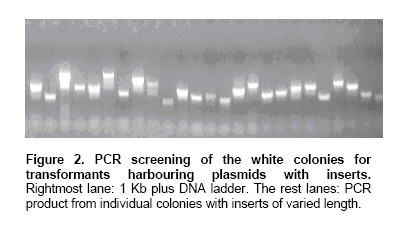
1). Sixty colonies were randomly picked for colony PCR using AP11 primer.
All of them harbouring plasmids with inserts of expected size (Figure
1 and Figure 2).
Plasmids were extracted from the colonies and inserts sequenced
using M13 forward/reverse primer. Of the 272 colonies for sequencing, 259 were
non-redundancy sequences, and 119 were found to have unique SSR inserts (Table
1). All of the six probes used could be directly related to these sequences;
the (cgc) 4 SSR was an only exceptional case. The ratio of non-redundant SSR
inserts was 43.7%. Although it may not be the highest in groundnut SSR isolation,
due to the judicious choice of restriction enzymes, and a probe removal step
for uprooting probe-primed PCR, most of these SSRs identified were found to
possess flanking sequences needed for primer design; we were able to design
123 “good” primer pairs for further evaluation. In Hopkins's report, 66 (55.0%)
out of the 120 sequenced “positive” clones had SSRs, but only 26 (21.7%) primer
pairs could be designed, where both the occurrence of short tandem repeats
(<6 core unit) and the close proximity of the SSR to the end of insert DNA
limited the ability to design primers for the majority of the SSRs identified
(Hopkins et al. 1999). Gao et al. (2003) identified
14 (5.5%) unique SSR-containing sequences in 256 clones. He et
al. (2003) sequenced 401 randomly picked clones resulting from AFLP pre-amplification
based protocol, 83 (20.7%) of which were unique SSRs, and 56 (14.0%) primer
pairs were designed. Moretzsohn et al. (2004) pre-screened
the clones before sequencing using SSR-anchored PCR strategy and found 162
of the 750 clones had SSRs. There were 91 unique sequences, but only 67 were
suitable for primer design (41.4% of positive clones). Ferguson
et al. (2004) identified 348 (21.3%) SSRs by sequencing 1,627 clones, merely
226 (13.9%) primers could be designed.
Table 1. Property of the newly identified
groundnut SSRs.
|
Sequence ID
|
Repeat
motifs
|
Type
|
Primer ID
|
Primer sequence
(Foward)
|
Primer sequence
(Reverse)
|
CTW-06
|
(ct)27
|
perfect
|
S-01
|
TGGACTAGACAAGGAACAACCA
|
GAGCCATGAGCACACAACAC
|
CTW-06
|
(ct)4
|
perfect
|
|
|
|
CTW-07
|
(gaa)5
|
perfect
|
S-02
|
TTGTTGCTATTTAGGGTGATTGA
|
GTGGGACAAGGCTTTGTTGT
|
CTW-07
|
(gaa)5
|
perfect
|
|
|
|
CTW-07
|
(aac)5
|
perfect
|
|
|
|
CTW-10
|
(tct)5
|
perfect
|
S-03
|
GCACCAATTTTGTCCCTGAT
|
AAGGGGTTTGCACGTAAATG
|
CTW-11
|
(ca)10(ct)8
|
compound
|
S-04
|
GAACGCCAGTTTACGTCGTC
|
TTGGGACACTTACCGAAGAGTT
|
CTW-11
|
(ct)4
|
perfect
|
|
|
|
CTW-13
|
(ac)53
|
perfect
|
S-05
|
CCGGCTAGAGAATACACACACA
|
CCGGCTAGAGAATACACACACA
|
CTW-13
|
(ca)4
|
perfect
|
|
|
|
CTW-13
|
(ca)4
|
perfect
|
|
|
|
CTW-14
|
(ac)84
|
perfect
|
S-06
|
CCGGCTAGAGAATACACACACA
|
TCCTCCTTCCTCCTTGAACA
|
CTW-15
|
(tct)5
|
perfect
|
S-07
|
GCACCAATTTTGTCCCTGAT
|
CAGAAGGGGTTTGCACCTAA
|
CTW-16
|
(ac)12
|
perfect
|
S-08
|
AAGTCCAAAATGCATGCTCA
|
GGCTCTGTGTGGTAGGGTGT
|
CTW-18
|
(ag)5
|
perfect
|
S-09
|
CGCTGTCCTTATCGAACCAT
|
CTCTCACTCGCGCTTTCTCT
|
CTW-18
|
(ca)4
|
perfect
|
|
|
|
CTW-18
|
(ga)4
|
perfect
|
|
|
|
CTW-18
|
(ga)4
|
perfect
|
|
|
|
CTW-19
|
(gt)32
|
perfect
|
S-10
|
CAAGCCAAAAGTGGAAAACC
|
TCCTTTTGCTAATGCGGTCT
|
CTW-19
|
(gt)4
|
perfect
|
|
|
|
CTW-19
|
(ct)5
|
perfect
|
|
|
|
CTW-20
|
(ct)4tt(ct)9
|
imperfect
|
S-11
|
ATGACGGCAGTAGCAGAAGC
|
TTGAGGAGAAGACGCTGTTG
|
CTW-20
|
(tc)4
|
perfect
|
|
|
|
CTW-20
|
(ct)4
|
perfect
|
|
|
|
CTW-21
|
(caa)3cca(caa)2
|
imperfect
|
S-12
|
TCATTGACCTAGCCGAATCC
|
GAGGGACCAATTGTTGGTTG
|
CTW-23
|
(aac)5
|
perfect
|
S-13
|
TTGTTGCTATTTAGGGTGATTGA
|
CGTCGTTTGATTCATGTAGCC
|
CTW-23
|
(gaa)5
|
perfect
|
|
|
|
CTW-23
|
(gaa)5
|
perfect
|
|
|
|
CTW-25
|
(ca)12
|
perfect
|
S-14
|
AGGCAAACCACTGCAAGAGT
|
CGCTTCCCTGGGATACTTAG
|
CTW-26
|
(ctt)5
|
perfect
|
S-15
|
TGAACGAAAAATGCTAATGTGG
|
CGCAGAGACGTGTTGAAGAA
|
CTW-26
|
(ctt)5
|
perfect
|
|
|
|
CTW-26
|
(ctt)4
|
perfect
|
|
|
|
CTW-28
|
(tc)9
|
perfect
|
S-16
|
TGGTAGTGGAGTCAGAGTGTGTG
|
GTTGCATTGCCCAACTCTTT
|
CTW-28
|
(gt)4
|
perfect
|
|
|
|
CTW-29
|
(ct)16
|
perfect
|
S-17
|
CATTGGAAAGATCCGACGAT
|
GTTGCAACAACGACGATGG
|
CTW-29
|
(ct)4
|
perfect
|
|
|
|
CTW-31
|
(ct)5
|
perfect
|
S-18
|
CAATAAATTCGTCGTAT
|
GAGAGAAGAGAAGGTTAGAGA
|
CTW-33
|
(ct)24
|
perfect
|
S-19
|
GCTCCACTAGTGCCGAAATC
|
CAGACACCCGGAGGCTTA
|
CTW-36
|
(caa)5
|
perfect
|
S-20
|
CACGAACAGCCACTCAAAGA
|
CTCTGGGGGACTAGCTGTTG
|
CTW-39
|
(ct)15
|
perfect
|
S-21
|
AGTCCTACTTGTGGGGGTTG
|
TCCCTTTTGCAGTGAAATCC
|
CTW-41
|
(ac)8(at)5
|
compound
|
S-22
|
CGTGACAAACATGTGCTGCT
|
TTTTGGAATCTGTTTATGGGAAA
|
CTW-51
|
(tgt)4
|
perfect
|
S-23
|
CTGGAAGTGGTCCTGTTGGT
|
GCTGCTCCTGTCTCTGGAAT
|
CTW-52
|
(ga)22
|
perfect
|
S-24
|
GGCAATGCACACGCTACTCT
|
CGTGAGGCGTGAGAGTTCAT
|
CTW-54
|
(aga)7
|
perfect
|
S-25
|
GCTATGCTTTTACCACACCAAA
|
CCATTCATGGTCATCCCTTC
|
CTW-54
|
(ag)4
|
perfect
|
|
|
|
CTW-56
|
(aac)4
|
perfect
|
S-26
|
ACATGAGTGCCCAACTAGCC
|
TGCAGAGCTTCAACAACCAC
|
CTW-66
|
(ca)4
|
perfect
|
S-27
|
ATCCGGCTCACAGTTCAATC
|
GCCAAGGCTGAAAAGAGTTG
|
CTW-68
|
(ttg)4
|
perfect
|
S-28
|
TTGCAAGATGTGCATCAAAA
|
TGACAAACCAACAAACGACA
|
CTW-68
|
(gt)4
|
perfect
|
|
|
|
CTW NEW_67
|
(ttc)15
|
Perfect
|
S-29
|
CACCGCCGCCCGTTTCTTCTCCT
|
GGGCAACGGCTCGACGGTGGTATC
|
CTW NEW_67
|
(cct)5
|
perfect
|
S-30
|
CTTCTTCTTCTTCCCGCCACC
|
GGCGGGCGACGGGCAAC
|
CTW NEW_124
|
(tc)3tt(tc)10tt(tc)4
|
imperfect
|
S-31
|
GGCGGCGATGTAGAACCCTCCAGTAG
|
ACCGCCATCGCCATCGTTGTTGT
|
CTW NEW_174
|
(ct)2cc(ct)19
|
imperfect
|
S-32
|
GCATTCGCGCAGCAACC
|
CCAGAGTAGAGCGGCAGTCC
|
CTW NEW_270
|
(caa)4
|
perfect
|
S-33
|
AGATCGCCGCCCTTACCAAAACCT
|
AGAAAGCCCCAAAATCGTGAGTAACAT
|
CTW NEW_263
|
(tgt)4
|
perfect
|
S-34
|
ACCTTCTTCCGCGCTTGTTTCAG
|
TCCCAGCTCCGATCCTCATACTTCA
|
CTW NEW_74
|
(ga)5
|
perfect
|
S-35
|
GCGGTTGCCTGGGTCGTC
|
CCGCAATGGAAGTGGGAAAGTAT
|
CTW NEW_227
|
(tct)6
|
perfect
|
S-36
|
GGCAACGCGTGGTAGCAGTG
|
GAGTGAGTGAACCAGAAGGAAGGA
|
CTW NEW_33
|
(gt)8
|
perfect
|
S-37
|
GACCGCGGCTCCACTTCTTTCTCT
|
ACATTCCCCTTTCACCCCTCACAAC
|
CTW NEW_51
|
(ga)17
|
perfect
|
S-38
|
GGCAGCGAAGCACCCATTGTTA
|
GTAGGGTTGCGTTTCGTTTTCTTATCG
|
CTW NEW_72
|
(aca)4
|
perfect
|
S-39
|
TCCAAAATCAACCAGAAAGCAGAAGCAGATG
|
AGGAAGAGAAGCGGAGAGGGAGAGAAG
|
CTW NEW_204
|
(ca)7
|
perfect
|
S-40
|
ACCCAACACTAGCCGCCACTGA
|
GCAACGCCTCCTCCTCTTCCTCTA
|
CTW NEW_16
|
(aac)4
|
perfect
|
S-41
|
AGAGTATGCGGAATTTGTGCTGAT
|
CCCGTTGTTGGTTGTGATGG
|
CTW NEW_209
|
(caa)4
|
perfect
|
S-42
|
GAGGGGGCGAACGTTGGACTTG
|
GCCGGAGCACTTGAGCATTTTT
|
CTW NEW_7
|
(aga)6
|
perfect
|
S-43
|
ATTCTTTGGACTCGGGTTCATACTTTG
|
ACACCATCCCTCACTCTCCTCCATA
|
CTW NEW_197
|
(tg)17(ag)17
|
compound
|
S-44
|
GGTGTTGAGGGATGGTTGTTCTAA
|
CTTTCCCGCCTCTCCCTCTC
|
CTW NEW_62
|
(tga)5
|
perfect
|
S-45
|
AGGTGTTGTGGCATTGTTCTTCAT
|
CGGCGGTAGCGGTAGCGGTTAT
|
CTW NEW_77
|
(gaa)8
|
perfect
|
S-46
|
ATGGCGAATCGGAGGGTAGGTT
|
TCCAATCGTGCGTTTCAATCATCT
|
CTW NEW_19
|
(gtt)5
|
perfect
|
S-47
|
ATTCTGAGGCTGCTTCCCAAACT
|
CTGCCATGTAAGCCGTGAATAAG
|
CTW NEW_86
|
(gtt)5
|
perfect
|
S-48
|
ATTCTGAGGCTGCTTCCCAAACT
|
CTGCCATGTAAGCCGTGAATAAG
|
CTW NEW_36
|
(gt)11(ga)7ggaggaa(ga)6
|
compound
|
S-49
|
GGCAGCGAAGCACCCATTGT
|
CGTTTCGTTTTCTTATCGCACTTC
|
CTW NEW_241
|
(aac)4
|
perfect
|
S-50
|
ATGCACGCAACTACAGGAAGATAAC
|
TGCGCAAGAGAACGGAACAT
|
CTW NEW_71
|
(tc)7
|
perfect
|
S-51
|
CCCAATTCGCATAAAAACAGAGAC
|
CGAGCCGCAATCCAACACT
|
CTW NEW_74
|
(ga)5
|
perfect
|
S-52
|
CCCTGAGAATGAAAGAAAGAAACA
|
CAACCGCAGCGACGATAGATG
|
CTW NEW_92
|
(tct)6
|
perfect
|
S-53
|
CACACCCATCCATCTCCTCCATA
|
TGTCTTTGTTGCTCCTCCCTCATT
|
CTW NEW_234
|
(ca)5(ga)35
|
compound
|
S-54
|
GTGTGCCATGTAGGTGTGACTG
|
GTTTGCCCTCTTGTTTTCTCC
|
CTW NEW_37
|
(ag)5
|
perfect
|
S-55
|
ACCCCCAACTGCACTACTATTCATTTT
|
CGACGCGGCGAGGCTTCC
|
CTW NEW_202
|
(tc)16
|
perfect
|
S-56
|
CATAGGCGTCCCATTGCTTACAG
|
GATTACGCGCTCTTTCATTTG
|
CTW NEW_252
|
(ttg)9
|
perfect
|
S-57
|
AGGGCGAAAGGCAGAGGAAGA
|
AAAGGGGTGAGACAGCCAATAACAT
|
CTW NEW_231
|
(tc)5
|
perfect
|
S-58
|
GAGCGAAAGAGAACGAGACAACAA
|
TCGGGGAGGATCAACCAAATAG
|
CTW NEW_62
|
(gtt)4
|
perfect
|
S-59
|
TTGGTGGAAGCCCTAGAGTGAGTGAA
|
ATGGAAATGAAGCCGATAAGAGA
|
CTW NEW_92
|
(tc)5
|
perfect
|
S-60
|
TTGGTGCAGGGATGTAAATG
|
ATATGGAGGAGATGGATGGGTGTG
|
CTW NEW_137
|
(aac)4
|
perfect
|
S-61
|
GAGGAGGCAGAGATAATCAGG
|
GAGAGGTCTGCTGTTGGGTAT
|
CTW NEW_166
|
(tg)6
|
perfect
|
S-62
|
CAAGTGGGGGGTTTATGGTG
|
CCCCCTCCATCACCCCT
|
CTW NEW_200
|
(ag)13a(ag)2
|
imperfect
|
S-63
|
CACCGTGGTATGATCGTTTCTTTT
|
GTTCGCGTGGGATTGTTTGTGT
|
CTW NEW_51
|
(gt)11(ga)7gtgagga(ag)6
|
compound
|
S-64
|
GGCAGCGAAGCACCCATTGT
|
TCCTTCGACCCTATCTATCAGTATCAC
|
CTW NEW_67
|
(ctt)9
|
perfect
|
S-65
|
CGATACCACCGTCGAGC
|
CAAGAACCCAGAATCAGGAAG
|
CTW NEW_130
|
(tg)15
|
perfect
|
S-66
|
ACCCCCATTGAGCGATTTG
|
AGTCCCATTGCCTTTCTTCTGTAT
|
CTW NEW_157
|
(aac)6
|
perfect
|
S-67
|
TCTCCTTCCCGAACAACCCTATTA
|
ATTGTTGACTTGGCTTCGTTCCTA
|
CTW NEW_137
|
(aac)6
|
perfect
|
S-68
|
AATCAAGGTGGCAACTACAGC
|
AGACACTATACTTGCAACGAGGAT
|
CTW NEW_17
|
(ttc)4
|
perfect
|
S-69
|
GGGGAGTCGTGTCAAGCCATTA
|
ACCCCAAACCCAACCCTCAC
|
CTW NEW_43
|
(ttg)5
|
perfect
|
S-70
|
CCTTTCCCATTCCATTAGC
|
GTCCGAGTTGAGGAACAACAA
|
CTW NEW_88
|
(tct)7
|
perfect
|
S-71
|
ACCTCTTTCCCTCTCCTCCATA
|
TTCCTTGCCTCTGTTGTTTGAT
|
CTW NEW_139
|
(ag)6
|
perfect
|
S-72
|
TACAGCCCAAATGGAATGAGAA
|
GAGTTGGGAAGAAAGGATGAAGAT
|
CTW NEW_68
|
(aag)8
|
perfect
|
S-73
|
AGTCCACTGAACCGAACACCAATC
|
TCCCTACCACCGAACGAAACAAT
|
CTW NEW_20
|
(aac)9
|
perfect
|
S-74
|
GCACGCGCTCAGGACAAAT
|
AGGGCGAAAGGCAGAGGAA
|
CTW NEW_249
|
(ttc)4
|
perfect
|
S-75
|
ACACCCTCCTCAACATCAAAT
|
ATACCCAAGCGAAACAAGAATC
|
CTW NEW_36
|
(ga)18
|
perfect
|
S-76
|
ATACTGATAGATAGGGTCGAAGGAGAG
|
CAACGAAAGAAAAATAAGGACATAGTG
|
CTW NEW_194
|
(ct)9
|
perfect
|
S-77
|
CACCCCTCACTACAAGAAAAATAC
|
ATGGCGGAGAAGAGGGAGGAG
|
CTW NEW_199
|
(caa)6taa(caa)4
|
Imperfect
|
S-78
|
TCCAATTCAATCTCACTAAAAACT
|
CAAAGGGGAGCACGAACATAAG
|
CTW NEW_193
|
(ttc)5
|
perfect
|
S-79
|
AAACCACGCAGTCCGAATACA
|
CTTGATGGGCTTTGGAGATAA
|
CTW NEW_202
|
(tct)6
|
perfect
|
S-80
|
GGCGTCCCATTGCTTAC
|
AGAATGCGTTGATGTTATGAA
|
CTW NEW_119
|
(tc)26
|
perfect
|
S-81
|
GCTTCAGTGGTGGGCTCAT
|
TATCATAGTAAAAAGGTGGGAACAAT
|
CTW NEW_219
|
(tgt)4
|
perfect
|
S-82
|
TTGCAAAGTAGCGTTCAGAC
|
CATGGATGGCAGGACAAT
|
CTW NEW_271
|
(ca)15ta(ca)11
|
Imperfect
|
S-83
|
CTTGAACTTATTTTTGGTGGGTGAAC
|
CAAGGGAGAATGAAGAATGCTAAG
|
CTW NEW_274
|
(ga)9
|
perfect
|
S-84
|
CAGCCAATATGTCACAACCCTAAT
|
CTCCCACTACAAATCTCCAATCAAT
|
CTW NEW_178
|
(ct)12cc(ct)14
|
Imperfect
|
S-85
|
AAACTATCACCGACAAAAA
|
AGAGACATAAGCCGAGAGG
|
CTW NEW_32
|
(ttc)14
|
perfect
|
S-86
|
TCCATGAGGGGTTATAGGTGTTT
|
GGGTGTATTTCTGAAGTTCCATTATC
|
CTW NEW_67
|
(ggt)8
|
perfect
|
S-87
|
TCTGAGTTCTGGCTTTTGAT
|
CACCACCACCATCATCATCAT
|
CTW NEW_128
|
(ag)43
|
perfect
|
S-88
|
TCAAAGAAGCAATAAAAATC
|
CTCCACCGGCAAGCACCTC
|
CTW NEW_82
|
(ct)19
|
perfect
|
S-89
|
ATCTATGGCCGGGTTGGTT
|
AGGTGGTGGGTAGTGCTTCTG
|
CTW NEW_231
|
(ttc)11
|
perfect
|
S-90
|
GAGAGCGAAAGAGAACGAGAC
|
GAATTGGAATCCATAGCCAT
|
CTW NEW_162
|
(ttc)8(tcc)2(ttc)4
|
compound
|
S-91
|
TGAGGGCAGGGGAAGAT
|
CGTCGGTGGTTGAAGCAGAG
|
CTW NEW_219
|
(tgt)4
|
perfect
|
S-92
|
ATTGGCAGATGAAGAAGGA
|
GGGAAATCAGAGGTGGAATAA
|
CTW NEW_38
|
(tg)10(ag)14
|
compound
|
S-93
|
TTGGGGAAATACAGAATAACG
|
CTCCCACATCCCCACCAT
|
CTW NEW_185
|
(ag)25
|
perfect
|
S-94
|
TTCCCAAAAATAGTCAACCA
|
TCTTCCTCTGCCTTTCATCCA
|
CTW NEW_40
|
(ca)5
|
perfect
|
S-95
|
AACCCCAACCATCAAACAAACA
|
ATGGTATCACTGGGAAATG
|
CTW NEW_193
|
(tct)4
|
perfect
|
S-96
|
ATACACATTCCTCTCCATCTCCT
|
TTTTTCTTCCCTTTCTTCTTTCTA
|
CTW NEW_206
|
(ttg)13
|
perfect
|
S-97
|
GAATCGCGTCTCAGGTG
|
TATTGCTTACGATTATTTTGT
|
CTW NEW_225
|
(Ac)7
|
perfect
|
S-98
|
TTAATGAACCCAAATACACA
|
AGCCAAAACCCTAAAAACTA
|
CTW NEW_162
|
(ttc)7
|
perfect
|
S-99
|
GGGCAGGGGAAGATCAATA
|
ATGAGGGTGAATTGGAATTGG
|
CTW NEW_74
|
(ac)5
|
perfect
|
S-100
|
AAGCGCCATATGTGTTTGA
|
CCCGTCTTGGCTTTCTTCT
|
CTW NEW_220
|
(tca)4
|
perfect
|
S-101
|
AGTGCGTTTGGCTCATCA
|
ATTTCGTTCATTTAGTCCATAGA
|
CTW NEW_67
|
(tga)5
|
perfect
|
S-102
|
TCCTGATTCTGGGTTCTTGA
|
CCATCCACTGCCACTCCAT
|
CTW NEW_152
|
(gt)14
|
perfect
|
S-103
|
ATGTGGGAATTATGGGTAGC
|
ATGGCGTGACAAAAGAATC
|
CTW NEW_253
|
(ttg)8
|
perfect
|
S-104
|
GAATCGCGTCTCAGGTGGTTT
|
TTAGATGAGTATGAAGAGATTAT
|
CTW NEW_211
|
(ag)9
|
perfect
|
S-105
|
AAGCTCATTTCATCACAA
|
CCACAAACGGCTCATCAATC
|
CTW NEW_78
|
(gaa)11
|
perfect
|
S-106
|
GCCAGCATAGAAGCATAATAACA
|
GAGTAATAGTGAATCAATGAGAAGAGG
|
CTW NEW_277
|
(gaa)6
|
perfect
|
S-107
|
TTCAATAATCCAAACCTCATCA
|
CTGTTTGCGTTTTTCTACTCTG
|
CTW NEW_177
|
(tc)14(ac)15
|
compound
|
S-108
|
GCTTACATTACACGTCATCTC
|
CCGAACTTACAGTTAGGAG
|
CTW NEW_27
|
(ag)21
|
perfect
|
S-109
|
AAGGGAGCACAATCATA
|
GAGCACGAGTTCATACAC
|
CTW NEW_9
|
(aac)37
|
perfect
|
S-110
|
TTCTAGTAGTAAAAATAAAAACAC
|
GTCAAAGGGAGGCACGAACATAAGT
|
CTW NEW_136
|
(gt)20
|
perfect
|
S-111
|
TGAAAATTAAAACTACCAACTACA
|
TGCCCCAAGATAACACAAT
|
CTW NEW_254
|
(atg)4
|
perfect
|
S-112
|
ACTGCTAGCGTTGTTTTCTTCC
|
CATTACACCTTCACCAACACCA
|
CTW NEW_78
|
(tc)9
|
perfect
|
S-113
|
TTGCATGTAGGAAAGAAAGATT
|
TTGGATGTGGTGGTGATGT
|
CTW NEW_133
|
(ct)12
|
perfect
|
S-114
|
AAGAGACGAAAGTGAGTTAGC
|
GGGAGCATGTTTAGGGAGAC
|
CTW NEW_182
|
(cca)5
|
perfect
|
S-115
|
GGTAATATGCCTTGGTGAC
|
TTCTTGATAATTCTGTGGAT
|
CTW NEW_217
|
(ttc)4
|
perfect
|
S-116
|
GATTTGTTTTCTTCTTCGTTTTT
|
CATAATCCACTTCGCCCTAAT
|
CTW NEW_266
|
(ttg)8
|
perfect
|
S-117
|
GGATAAAATAAGGAATGA
|
TTGCAAGTAAGTAATACAA
|
CTW NEW_78
|
(aat)6
|
perfect
|
S-118
|
TATATGATGCTTGATTGAGACT
|
CATGTAGAAGGCTTGGAGGGTAT
|
CTW NEW_217
|
(ttc)4
|
perfect
|
S-119
|
CTTCTTCGTTCTTCTTCC
|
ACGCGTTAGTCTCACAGTCA
|
CTW NEW_35
|
(tc)25
|
perfect
|
S-120
|
TTCAAACTACATCTCAAACTAT
|
TGTGCCAGGACCCAAAAT
|
CTW NEW_8
|
(aca)4
|
perfect
|
S-121
|
TTCTCAAAGTCTGTCTGG
|
TTTAGCAATTGGTTCTTA
|
CTW NEW_32
|
(gaa)4
|
perfect
|
S-122
|
TTTTTCGATTTTCATGGTTTCTG
|
TTTCTCTTTCTCCTCATCTTCTGC
|
CTW NEW_12
|
(ct)11
|
perfect
|
S-123
|
GTATGGTGACTGTAGTTCTC
|
AGTGACCAAAATAGAAGC
|
CTW NEW_103
|
(tg)12
|
perfect
|
|
|
|
CTW NEW_104
|
(tgt)15
|
perfect
|
|
|
|
CTW NEW_12
|
(cgc)4
|
perfect
|
|
|
|
CTW NEW_171
|
(aac)6
|
perfect
|
|
|
|
CTW NEW_184
|
(tc)24
|
perfect
|
|
|
|
CTW NEW_190
|
(ttg)7
|
perfect
|
|
|
|
CTW NEW_194
|
(tc)8
|
perfect
|
|
|
|
CTW NEW_215
|
(gga)4
|
perfect
|
|
|
|
CTW NEW_222
|
(ct)24
|
perfect
|
|
|
|
CTW NEW_223
|
(tg)35
|
perfect
|
|
|
|
CTW NEW_227
|
(ct)21
|
perfect
|
|
|
|
CTW NEW_23
|
(ca)28
|
perfect
|
|
|
|
CTW NEW_257
|
(tg)26
|
perfect
|
|
|
|
CTW NEW_259
|
(tg)11(ag)13tg(ag)10
|
compound
|
|
|
|
CTW NEW_277
|
(gaa)4gga
(gaa)gag
(gaa)6cgc
(gaa)taga
(gaa)40
|
imperfect
|
|
|
|
CTW NEW_52
|
(tg)51
|
perfect
|
|
|
|
CTW NEW_58
|
(ct)31
|
perfect
|
|
|
|
CTW NEW_67
|
(tga)4(tgg)7
|
compound
|
|
|
|
CTW NEW_68
|
(agg)4
|
perfect
|
|
|
|
CTW NEW_85
|
(tg)7
|
perfect
|
|
|
|
CTW NEW_97
|
(tc)13
|
perfect
|
|
|
|
CTW NEW_98
|
(tg)12
|
perfect
|
|
|
|
In contrast to previous reported SSR isolation protocols,
our simplified protocol utilized 4 enzymes to cut groundnut DNA into ideally
sized fragments which were ligated to adaptors in a single tube. The present
SSR enrichment protocol adopted a multiple enzyme digestion/ligation procedure
apparently similar to AFLP pre-amplification based protocol, but the product
in our protocol was in the range of 200-1000 bp, whereas in groundnut EcoR
I/Mse I AFLP protocol, the pre-amplification product was generally between
70 and 500 bp. Too short DNA sequences in the latter case may increase the
possibility of lack of adequate flanking sequences. With the advance in sequencing
facility and technology, the number of base pairs of DNA readable in a single
sequencing reaction tends to be longer and longer, and DNA inserts of ~1000
bp do not necessarily mean more cost.
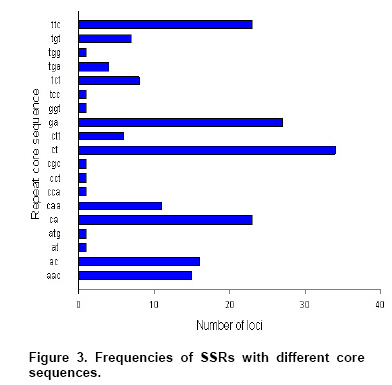
It can be seen from the Figure
3 that ct/ag repeat motif had the highest frequencies, followed by ga/tc,
ttc/gaa and ca/tg. Indeed, ct/ag repeat was reported to be rich in other
plant species, and was the most frequently dispersed SSRs of groundnut in
He's report (He et al. 2003). The results to some extent
may reveal the relative abundance of different repeat motifs as well as the
ease of capture.
The copy number of the SSR core sequences was also highly
variable. SSRs, even for 3-nucleotide core sequences, with copy number higher
than 40 were not strange. The number of repeats may exceed 80.
In the present study, of the 123 newly designed primer pairs
tested in 12 peanut varieties/lines mainly bred in Shandong province, China,
only 44 (35.8%) produced polymorphic bands (Huang et al. 2006).
Despite the fact that several hundreds of SSRs have been isolated from groundnut,
only a small portion of them showed polymorphic in the cultivated groundnut,
far from the need for map construction let alone QTL mapping. Strengthening
groundnut SSR development is absolutely necessary. Compared to previous protocols
reported in groundnut, the present protocol was efficient, time-saving and
easy to follow. In all previous reports without exceptions, the cultivated
groundnut was the only plant material used to isolate groundnut SSRs; in this
study, a hybrid derivative was exploited instead. Considering the polyploidy
nature of the groundnut crop and frequent occurrence of multiple banding patterns
in groundnut SSR analysis, use of the inter specific hybrid derived material
makes it possible to isolate SSRs originated from both cultivated and wild
groundnut.
- BUROW, Mark D.; SIMPSON, Charles E.; STARR,
James L. and PATERSON, Andrew H. Transmission genetics of chromatin from
a synthetic amphidiploid to cultivated peanut (Arachis hypogaea L.):
broadening the gene pool of a monophyletic species. Genetics, October
2001, vol. 159, no. 2, p. 823-837.
- FERGUSON, M.E.; BUROW, M.D.; SCHULZE, S.R.;
BRAMEL, P.J.; PATERSON, A.H.; KRESOVICH, S. and MITCHELL, S. Microsatellite
identification and characterization in peanut (Arachis hypogaea L.). Theoretical
and Applied Genetics, April 2004, vol. 108, no. 6, p. 1064-1070. [CrossRef]
- GAO, G.O.; HE, G.-H. and LI, Y.-R. Microsatellite
enrichment from AFLP fragments by magnetic beads. Acta Botanica Sinica,
November 2003, vol. 45, no. 11, p. 1266-1269.
- HALWARD, T.; STALKER, H.T. and KOCHERT,
G. Development of an RFLP linkage map in diploid peanut species. Theoretical
and Applied Genetics, November 1993, vol. 87, no. 3, p. 379-384. [CrossRef]
- HE, Guohao; MENG, Ronghua; NEWMAN, Melanie;
GAO, Guoqing; PITTMAN, Roy N.
and PRAKASH, C.S. Microsatellites as DNA markers in cultivated peanut (Arachis
hypogaea L.). BMC Plant Biology, April 2003, vol. 3, p. 3. [CrossRef]
- HOPKINS, M.S.; MITCHELL, S.E.; CASA, A.M.;
WANG, T.; DEAN, R.E.; KOCHERT, G.D. and KRESOVICH, S. Discovery and characterization
of polymorphic simple sequence repeats (SSRs) in peanut. Crop Science,
July-August 1999, vol. 39, no. 4, p. 1243-1247.
- HUANG, Xinyang; WANG, Chuantang; YANG,
Xindao and XU, Jianzhi. Analysis of DNA polymorphism in peanut cultivars
using new microsatellite markers. Chinese Agricultural Science Bulletin,
2006, vol. 22, no. 10, p. 44-48.
- KRISHNA, Girish Kumar; ZHANG, Jinfa F.;
BUROW, Mark; PITTMAN, Roy N.; LU, Yingzhi; PUPPALA, Naveen and DELIKOSTADINOV,
Stanko G. Genetic diversity analysis in Valencia peanut (Arachis hypogaea L.)
using microsatellite markers. Cellular and Molecular Biology Letters,
2004, vol. 9, no. 4a, p. 685-697.
- MORETZSOHN, Marcio de Carvalho; HOPKINS,
Mark S.; MITCHELL, Sharon E.; KRESOVICH, Stephen; VALLS; Jose Francisco M.
and FERREIRA, Marcio Elias. Genetic diversity of peanut (Arachis hypogaea L.)
and its wild relatives based on the analysis of hypervariable regions of
the genome. BMC Plant Biology, July 2004, vol. 4, p. 11. [CrossRef]
- MORETZSOHN, M.C.; LEOI, L.; PROITE, K.;
GUIMARÃES, P.M.; LEAL-BERTIOLI, S.C.; GIMENES, M.A.; MARTINS, W.S.;
VALLS, J.F.M.; GRATTAPAGLIA, D. and BERTIOLI, D.J. A microsatellite-based,
gene-rich linkage map for the AA genome of Arachis (Fabaceae). Theoretical
and Applied Genetics, October 2005, vol. 111, no. 6, p. 1060-1071. [CrossRef]
- WANG, Chuan-Tang; YANG, Xin-Dao; CHEN,
Dian-Xu. DNA molecular markers in peanut. I. Developing a technical protocol
for peanut AFLP assays and screening for highly polymorphic parents for mapping. Journal
of Peanut Science, 2004, vol. 33, no. 4. p. 5-10.
- YANG, Xin-Dao, WANG, Chuan-Tang; CHEN,
Dian-Xu; ZHANG, Jian-Cheng; XU, Jian-Zhi and LIU, Guang-Zhen. Simple sequence
repeats in cultivated peanut as reveals by GenBank inquiry. Journal of
Peanut Science, 2005, vol. 34, no. 2, p. 14-16.
Note: Electronic Journal of Biotechnology is not responsible
if on-line references cited on manuscripts are not available any more after
the date of publication.
Supported by UNESCO / MIRCEN network
© 2007 by Pontificia Universidad Católica de
Valparaíso -- Chile
The following images related to this document are available:
Photo images
[ej07046f3.jpg]
[ej07046f1.jpg]
[ej07046f2.jpg]
|

{kind=link}
{kind=link}
{kind=link}