 |
| About Bioline | All Journals | Testimonials | Membership | News |
|
||||||
|
||||||
Electronic Journal of Biotechnology, Vol. 13, No. 5, September 15, 2010 Identification of SSR markers using soybean (Glycine max) ESTs from globular stage embryos Ai Qin Li#1, Chuan Zhi Zhao#1, Xing Jun Wang*2, Zhan Ji Liu1, Li Feng Zhang3, Guo Qi Song1, Juan Yin1, Chang Sheng Li1, Han Xia1, Yu Ping Bi1
1High-Tech
Research Center
Shandong Academy of Agricultural Sciences
Key Laboratory for Genetic Improvement of Crop, Animal
and Poultry of Shandong Province
Key Laboratory of Crop Genetic Improvement and Biotechnology
Huanghuaihai, Ministry of Agriculture
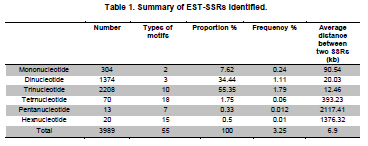
Ji’nan 250100, P.R. China #These authors contributed equally to this paper Financial support: This work was supported by Shandong Provincial Natural Sciences Foundation, China (Y2008D44), Shandong province “Taishan Scholar” foundation, Doctoral Foundation of Shandong Province (2006BS06008) and grants from Shandong Academy of Agricultural Sciences (2007YCX001, 2006YBS001). Code Number: ej10050 Microsatellites, or simple sequence repeats (SSRs), in expressed sequence tags (ESTs) provide an opportunity for low cost SSR development. We looked for EST-SSRs in 403,511 ESTs (generated by 454 sequencing and representing 70,654 contigs and 52,082 singletons) from soybean globular stage embryos. Among 122,736 unique ESTs, 3,729 contained one or more SSRs. In total, 3,989 SSRs were identified including 304 mono, 1,374 di, 2,208 tri, 70 tetra, 13 penta and 20 hexanucleotide SSRs. Thirty three EST-SSRs were selected for primer design and polymorphism analysis using twenty soybean cultivars and one wild-type soybean. Successful amplification was obtained using 21 of these primer pairs, 11 of which detected polymorphisms in these soybean cultivars. These results demonstrated that 454 high throughput sequencing is a powerful tool for molecular marker development. From the 3,989 identified SSRs we expect to obtain a large number of makers with polymorphism among different soybean cultivars, which would be useful for analysis of genetic diversity and maker assisted selection in the soybean breeding programs. Keywords: 454 sequencing, EST, Glycine max, polymorphism, SSR.
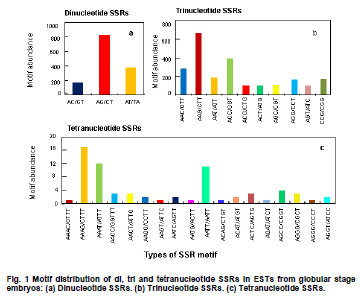
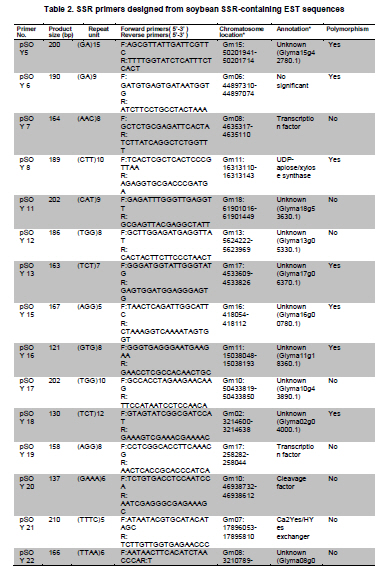
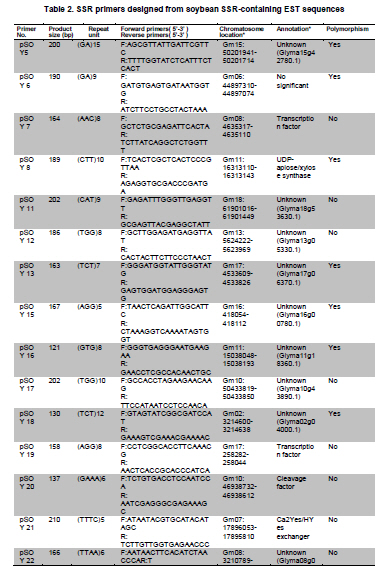
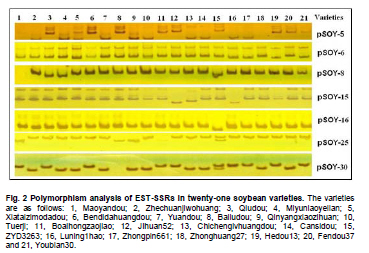
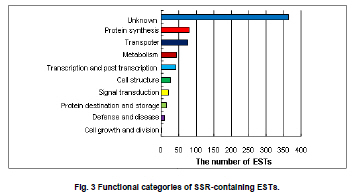
Soybean (Glycine max L.) is an important crop plant worldwide and has been used in China for 5000 years as source of vegetable oil and food. The soybean genome has been proposed as a model for phaseoloid legumes due to its economic and biological importance, moderate genome size (1.12-1.81 x 109 bp), and its extensive research history (Xia et al. 2007). There are more than 20,000 soybean varieties in China, most of which were derived from hybridization between limited fine strains and therefore have narrow genetic diversity (Qiu et al. 2000). To widen the genetic diversity of cultivars in future breeding programs, breeders need to know the genetic background of the germplasms they are using. Characterization of current germplasms, for example, by labeling of agronomically valuable traits with molecular markers, is of fundamental importance in this aspect. Reliable molecular marker development and polymorphism analysis of germplasms are plausible first stages in this varietal characterization. Microsatellites, or simple sequence repeats (SSRs), have greater potential in polymorphism analysis and marker assisted selection than other types of molecular markers (Thiel et al. 2003; Jiang et al. 2006). However, the conventional development of SSR markers by SSR enriched genomic library construction and large-scale sequencing is costly and labor intensive (Varshney et al. 2002). The occurrence of SSRs in ESTs provides an opportunity to use currently available ESTs in databases for SSR development (Qiu et al. 2000). This strategy has been used successfully in plant species such as grape (Vitis vinifera L.) (Scott et al. 2000), wheat (Triticum aestivum L.) (Hackauf and Wehling, 2002; Peng and Lapitan, 2005), barley (Hordeum vulgare L.) (Thiel et al. 2003), strawberry (Fragaria x ananassa) (Folta et al. 2005), orange (Citrus sinensis osbeck) (Jiang et al. 2006), foxtail millet (Setaria italica) (Jia et al. 2007), ryegrass (Lolium perenne) (Asp et al. 2007), blackberry (Rubus L) (Lewers et al. 2008). SSRs are widely distributed in the soybean genome, with an average interval of about 15 Kb between SSRs (Wang et al. 1994). By the end of 2008, about 330,436 soybean ESTs from diverse tissues and organs were present in GmGI (http://www.tigr.org/tigr-scripts/tgi/T_index.cgi), in which 37,308 SSRs were identified (Jayashree et al. 2006). Recently, Dr. Goldberg’s laboratory at the University of California, Los Angeles, submitted more than 400,000 ESTs from libraries of soybean globular stage embryos to the database (http://estdb.biology.ucla.edu/seed/sequence/).This huge number of ESTs was generated by 454 high throughput sequencing technology and provides a new opportunity for discovering molecular makers from genes that are active during early embryogenesis. The aim of this study is to develop EST-SSRs from globular stage embryos and examine its polymorphism among one wild type and 20 soybean cultivars. The polymorphic SSR makers would be important for genetic diversity analysis and marker assisted selection for soybean. We obtained EST sequences from the Goldberg laboratory, which used high throughput 454 sequencing to survey the transcriptome of soybean globular stage embryos (http://estdb.biology.ucla.edu/seed/sequence). Primer sequences were trimmed by SeqClean software (http://compbio.dfci.harvard.edu/tgi/software/). The 403,511 cleaned sequences were clustered and assembled by Tgicl and Cap3. Due to the large number of ESTs, Tgicl was unable to process all these sequences together. Instead, we grouped these sequences into three large groups and used Tgicl to process one group at a time. The resulted clusters were processed by Cap3 with p = 90 and y = 30. The contigs and singletons generated by Cap3 were subjected for microsatellite discovery by PERL5 script (MISA). The criteria used in this study were as follows: no less than sixteen repeats in single nucleotide SSRs; six or more repeats in di-nucleotide SSRs; and five or more repeats in tri-, tetra-, penta- and hexa-nucleotide SSRs. Randomly, 33 PCR primer pairs, which covered the di, tri, tetra, penta and hexanucleotide SSRs, were designed by primer premier 5.0 for amplification and polymorphism analysis. Twenty Chinese cultivars and one wild-type soybean (ZYD3263) were used for polymorphism analysis. These cultivars included four varieties from Beijing (Miyunlaoyelian, Zhongpin661, Zhonghuang27, and Youbian30), seven varieties from Hebei (Maoyandou, Xiataizimodaodou, Bendidahuangdou, Yuandou, Tuerdou, and Jiguan52), three varieties from Henan (Zhechuanjiwohuang, Qinyangxiaozihuang, and Boaihongdouzaojiao), three varieties from Shandong (Qiudou, Luning1, and Hedou13) and three from Shanxi (Bailudou, Cansidou, and Fendou37). These soybeans were grown in pots containing soil mixture at 25ºC for two weeks. Young leaves were collected for genomic DNA extraction using a Plant Genomic DNA Extraction Kit (Solarbio Inc., Beijing, China). PCR mixtures (20 µl volume) contained 1 x PCR buffer, 1.5 µM MgCl2, 200 µM dNTPs, 0.2 µM of each primer, 0.1U Taq polymerase (TaKaRa Inc., Dalian, China) and 10 ng genomic DNA as the template. Amplifications were performed in a TaKaRa PCR thermal cycler Dice TP600 with the following conditions: 94ºC for 4 min, 31 cycles of 94ºC for 30 sec, 55ºC for 30 sec and 72ºC for 30 sec, and a final extension step of 72ºC for 7 min. PCR products were separated on 6.5% w/v denaturing polyacrylamide gels (19:1 acrylamide/bisacrylamide, 7 M urea) and visualized by silver staining (Gao et al. 2009). The sizes of the amplified fragments were estimated based on Φ x 174-HaeIII digested DNA Markers (TaKaRa Inc., Dalian, China). Results and DiscussionIdentification of SSRs in soybean In total, 70,654 contigs and 52,082 singletons were generated from 403,511 cleaned ESTs. The average lengths of singletons and contigs were 177 bp and 268 bp, respectively. These non-redundant ESTs represented 28.1 Mb of cDNA. From these 122,736 non-redundant sequences 3,989 SSRs within 3,729 unique ESTs were identified. The SSR frequency in these soybean ESTs was approximately 3.3%, which was similar to frequencies obtained in several other plants (1.5% in maize, 4.7% in rice and 5.7% in lolium) (Kantety et al. 2002; Kumpatla and Mukhopadhyay 2005; Asp et al. 2007). However, there were fewer SSRs in these ESTs than that found in eucalyptus (29%) and citrus (21%) (Ceresini et al. 2005; Jiang et al. 2006). There were 235 (0.19%) unique ESTs that contained more than one SSR. This ratio was much lower than that in cattle (0.34%) (Yan et al. 2008) and citrus (3.4%) (Jiang et al. 2006). One important reason for this difference was that 454 sequencing-generated ESTs were shorter than ESTs generated by conventional methods. It is reasonable to assume that there is less chance of finding multiple SSRs in a short sequence than in a long one. Furthermore, the overall abundance of SSRs can vary depending on the criteria used to identify SSRs. Investigation of the distribution of SSR motifs can provide insight into the composition of the genome (Yan et al. 2008). Our results showed that the motif types and abundance of soybean SSRs were not evenly distributed. Trinucleotide SSRs were the most abundant, accounting for 55% of the total SSRs identified in this study. The 1,374 (34.44%) dinucleotide SSRs represented the second most abundant type of motif. The mononucleotide, tetranucleotide, pentanucleotide and hexanucleotide SSRs were shown to be minor types of soybean SSRs. The length of these SSRs varied from 12 to 114 bp depending on number of repeats of the motif in each SSR (Table 1). In total, 55 types of repeat motif were identified from these soybean ESTs. Among the mononucleotide repeats, the A/T motif (291) was much more prevalent than the C/G motif (13). AG/CT was the most abundant repeat, accounting for 60% of dinucleotide repeats, which agreed with reports in other crops (Cardle et al. 2000; Kantety et al. 2002; Asp et al. 2007). AT/TA and AC/GT repeat motifs were the second and third most abundant dinucleotide motifs, accounting for 27% and 13%, respectively (Figure 1A). AAG/CTT represented the most abundant (30%) trinucleotide motifs, followed by ACC/GGT (17%). The majority of these motifs were repeated 5-10 times in the ESTs examined (Figure 1B), which agreed with a report from citrus (Jiang et al. 2006). However, in foxtail millet (Jia et al. 2007) and eucalyptus (Ceresini et al. 2005). the most commonly identified trinucleotide motifs were CAG/TCT and CCG/CGG, respectively. Among the tetranucleotide motifs, AAAG/CTTT was the most abundant motif and AAAT/ATTT ranked as the second, which was in accordance with results from citrus (Figure 1C) (Jiang et al. 2006). In the case of pentanucleotide motifs, AAAAT/ATTTT and AACAT/ATTGT represented the most abundant identified SSRs. We found 15 different types of hexanucleotide repeat motifs, among which the A/T content (55.2%) was higher than C/G content (44.8%). The hexanucleotide repeat motifs occurred with roughly equal abundance. PCR amplification and polymorphism analysis Twenty-one out of 33 designed primers gave successful amplification within soybean cultivars tested. The details of primer sequences, amplified fragment size, annotation (if available) of the corresponding ESTs, SSR sequences and polymorphisms among the tested soybeans are listed in Table 2a & b. Importantly, 11 pairs of primers were able to detect polymorphisms in the tested soybean varieties (Figure 2). Interestingly, four ESTs corresponding to four of these SSRs, shared significant similarity to known proteins, namely UDP-apiose/xylose synthase, phosphate acyltransferase, plastidic phosphate translocator and acid phosphatase. It would be interesting to correlate these SSRs with a particular phenotype controlled by these genes. In this study, the functions of 3,097 (83%) sequences were not known. Only 632 (17%) of SSR-containing sequences were annotated. The function of these SSR-containing ESTs covered a wide range of biological processes, such as protein synthesis, signal transduction, cell structure, transport, metabolism, and disease and defense responses (Figure 3). We demonstrated that 454 high throughput sequencing is a powerful approach for discovering SSRs in plants. 454 sequencing could generate more than 200 thousand reads each run in a short time and with an affordable cost. Sequences generated by this technology have an average length of 200 bp, which is enough for SNP and SSR discovery. This study led to the discovery of 3,989 EST-SSRs from 403,511 soybean ESTs obtained by 454 sequencing. This number of EST-SSR accounts for 10% of total soybean EST-SSR found from the ESTs in the database so far. Of the 3,792 SSR containing uni-ESTs, 632 (17%) represented protein encoding genes, which making these EST-SSRs valuable in marker assisted selection. While 3,097 (83%) have no homolog sequences found in GenBank. One reason of the poor annotation is due to the short length of EST sequence (the average lengths of singletons and contigs were 177 bp and 268 bp). Another possible reason is that the ESTs used in this study derived from globular stage embryos and sequences available in the current database are mostly from mature tissues. However, ESTs contain less SSRs than that of the genomic sequences. Efficiency could be significantly improved, and more SSR markers could be identified, by applying 454 sequencing technology to SSR enriched genomic libraries. Due to the conserved genomic regions between different genome, SSR marker could be transferable among congeneric species (Boutin et al. 1995; Isobe et al. 2003; Kuleung et al. 2004). High transferability of EST-SSRs (34%) and genomic SSR (25%) between soybean and cultivated peanut were reported (He et al. 2006; Hong et al. 2010). As an important oil crop, marker development of peanut was far behind soybean and many other crops. These soybean EST-SSRs provided a useful molecular maker source for peanut. In this study we randomly selected 33 SSR containing ESTs and designed primers to amplify the SSRs. Twenty-one achieved successful amplification. The twelve instances where amplification was not achieved were mainly due to poor primer quality. The length of these ESTs ranged from 100 bp to 250 bp. If the SSR were located close to one end of the sequence, it would be very difficult to use the franking region for primer designing. Integrating these soybean 454 sequences with soybean sequences from other sources available in the database could partially resolve this problem. Out of the 21 amplified SSRs, 11 showed polymorphism among the tested soybean cultivars and wild-type soybean. Based on this ratio we could expect to identify more than 1,300 SSRs with polymorphisms in different soybean cultivars. The polymorphism screening experiment was undertaken using all EST-SSRs identified in this study. The results of this study will greatly facilitate the study of soybean genetic diversity analysis and marker assisted selection. We would like to thank Professor Robert B. Goldberg of University of California, Los Angeles, for allowing us to use the soybean EST sequences prior to their submission to the public database.
Note: Electronic Journal of Biotechnology is not responsible if on-line references cited on manuscripts are not available any more after the date of publication. Copyright © 2010 by Pontificia Universidad Católica de Valparaíso -- Chile The following images related to this document are available:Photo images[ej10050f3.jpg] [ej10050t2b.jpg] [ej10050t2a.jpg] [ej10050t1.jpg] [ej10050f2.jpg] [ej10050f1.jpg] |
| |||||||||

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}